Exploring Modern Reasoning-Enabled Large Language Models for Language Understanding
- Degree Programme: MSc Artificial Intelligence
- Module: Individual Project (7CCSMPRJ)
- Supervisor: Dr. Helen Yannakoudakis
ACKNOWLEDGEMENT
I would like to thank my supervisor, Dr. Helen Yannakoudakis, for her excellent guidance and support throughout this project. Her advice was essential to my success.
I am also grateful to the authors of the ITALIC dataset for making their work public. A special thanks to Matteo Rinaldi for providing access to the Mult-IT dataset.
I want to thank my peers, Jenny Kong, Tomasz Bernacki, and Jamie Ogundiran, for the helpful discussions we had about the general field of cultural alignment in LLMs.
Finally, I would like to thank my family and friends for their constant support and encouragement.
ABSTRACT
This project investigates the performance gap between cultural knowledge and linguistic understanding in smaller Large Language Models (LLMs) for the Italian language. While models often possess broad cultural knowledge, they can struggle with specific language rules like morphology, orthography and general grammar.
The project delivered two novel contributions. The first was analytical, exploring whether the reasoning capabilities of modern reasoning-capable LLMs (typically used for mathematics and programming) could be applied to the largely unexplored domain of linguistics. This investigation confirmed that enabling a model's step-by-step "thinking" process significantly improved its performance on complex linguistic tasks, proving reasoning is a valuable tool for language understanding.
While effective, the reasoning process is slow and computationally expensive, making it impractical for many applications. The project therefore attempted to improve the models' faster, non-reasoning mode through standard LoRA fine-tuning. This successfully improved linguistic skills but also created a critical problem as the models completely lost their ability to "think". The project's second novel contribution was a technical solution to this trade-off: a hybrid training method. This technique fine-tunes models using a mixed dataset, combining standard question-answer pairs with synthetically generated Chain-of-Thought (CoT) examples from the target model itself.
This hybrid approach was highly successful. It enhanced linguistic performance in the fast, non-reasoning mode while also fully preserving and even improving the models' advanced reasoning capabilities. The result is a more effective and versatile tool for the Italian language.
NOMENCLATURE
| Symbol / Acronym | Description |
|---|---|
| AI | Artificial Intelligence |
| RLVR | Reinforcement Learning through Verifiable Rewards |
| LLM | Large Language Model |
| PEFT | Parameter Efficient Fine-Tuning |
| LoRA | Low-Rank Adaptation |
| B | Billion parameters |
| CoT | Chain-of-Thought |
| NLP | Natural Language Processing |
| NLU | Natural Language Understanding |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| RLHF | Reinforcement Learning via Human Feedback |
| ToT | Tree of Thoughts |
| CoD | Chain of Draft |
| CISC | Confidence-Informed Self-Consistency |
| SFT | Supervised Fine-Tuning |
| RL | Reinforcement Learning |
| ML | Machine Learning |
| GRPO | Group Relative Policy Optimisation |
| FFT | Full Fine-Tuning |
LIST OF TABLES
Table 9.1: Baseline Replication Results for Llama 3.1 8B Ita
| Category | Replicated Result (%) | Reference Result (%) | Difference (%) |
|---|---|---|---|
| Art | 70.78 | 70.10 | +0.68 |
| Civic Education | 71.50 | 71.22 | +0.28 |
| Current Events | 82.70 | 82.61 | +0.09 |
| Geography | 79.06 | 79.26 | -0.20 |
| History | 77.66 | 77.40 | +0.26 |
| Literature | 67.17 | 67.17 | 0.00 |
| Tourism | 71.33 | 71.73 | -0.40 |
| Lexicon | 81.31 | 81.51 | -0.20 |
| Morphology | 51.71 | 52.14 | -0.43 |
| Orthography | 52.29 | 53.04 | -0.75 |
| Synonyms | 81.27 | 81.15 | +0.12 |
| Syntax | 53.52 | 53.65 | -0.13 |
| Total | 70.32 | 70.49 | -0.17 |
Table 9.2: Baseline Replication Results for Mistral NeMo
| Category | Replicated Result (%) | Reference Result (%) | Difference (%) |
|---|---|---|---|
| Art | 66.02 | 66.33 | -0.31 |
| Civic Education | 69.71 | 69.27 | +0.44 |
| Current Events | 82.52 | 82.61 | -0.09 |
| Geography | 76.43 | 76.00 | +0.43 |
| History | 74.95 | 74.34 | +0.61 |
| Literature | 69.31 | 68.39 | +0.92 |
| Tourism | 67.45 | 67.76 | -0.31 |
| Lexicon | 79.90 | 79.37 | +0.53 |
| Morphology | 52.86 | 52.86 | 0.00 |
| Orthography | 56.23 | 55.61 | +0.62 |
| Synonyms | 74.03 | 74.25 | +0.22 |
| Syntax | 54.57 | 54.78 | -0.21 |
| Total | 68.68 | 68.53 | +0.15 |
Table 9.3: Performance of Reasoning Models with Reasoning Disabled
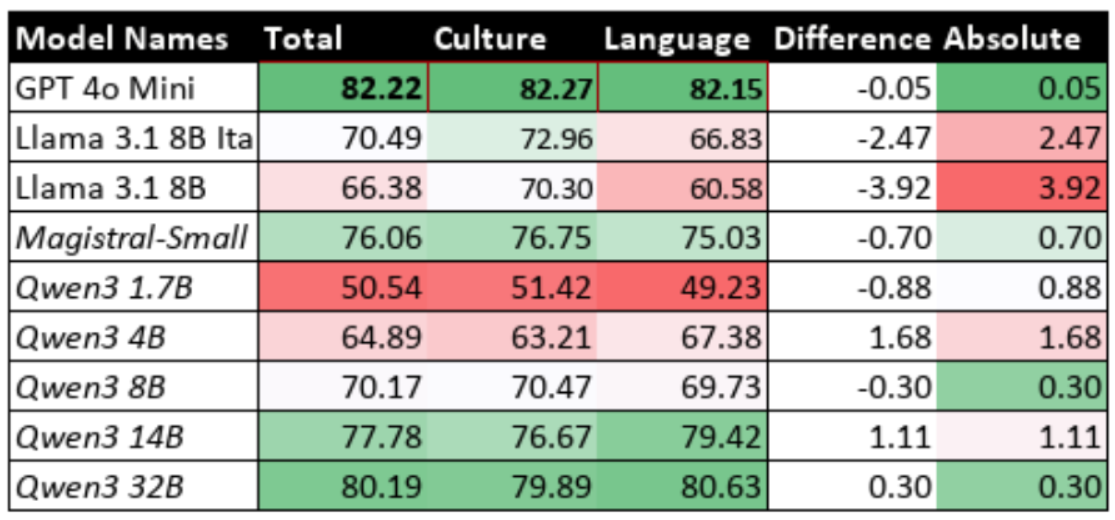
Table 9.4: Performance Change with Reasoning Enabled (%)
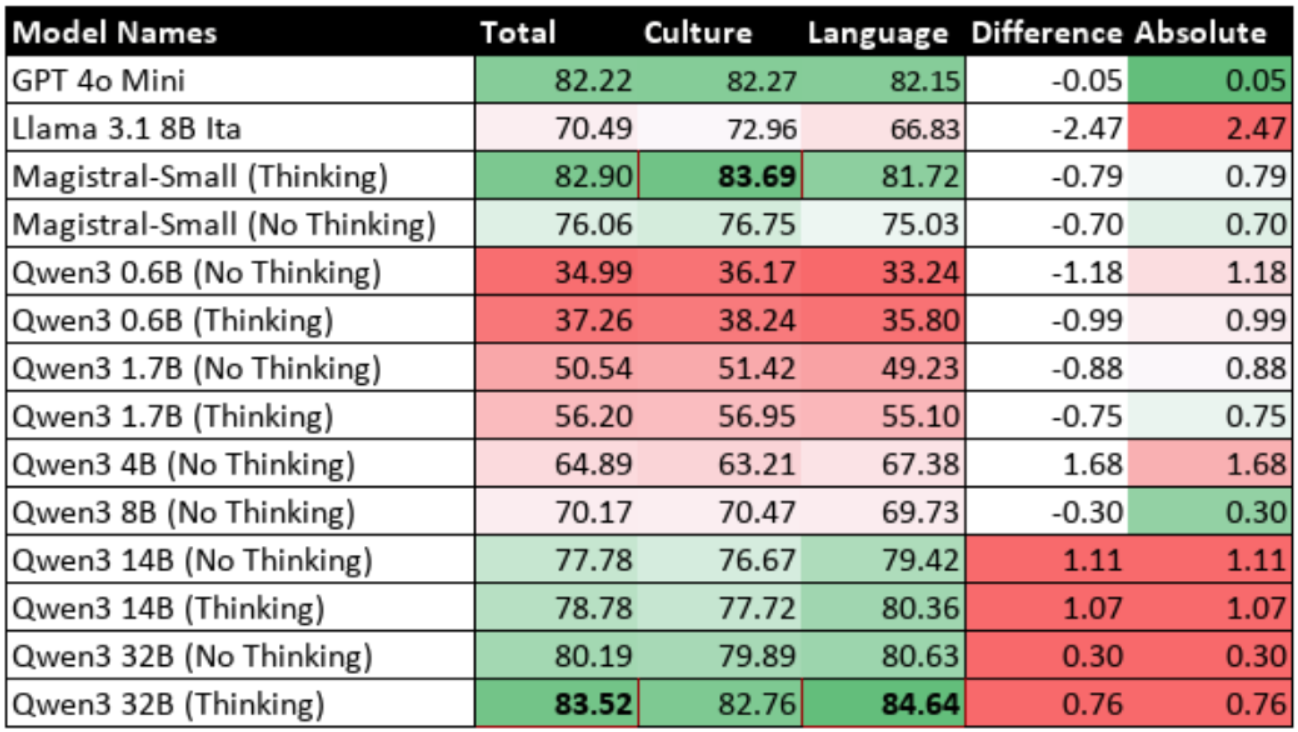
Table 9.5: Performance of Fine-Tuned Models with Reasoning Disabled (Iteration 1)
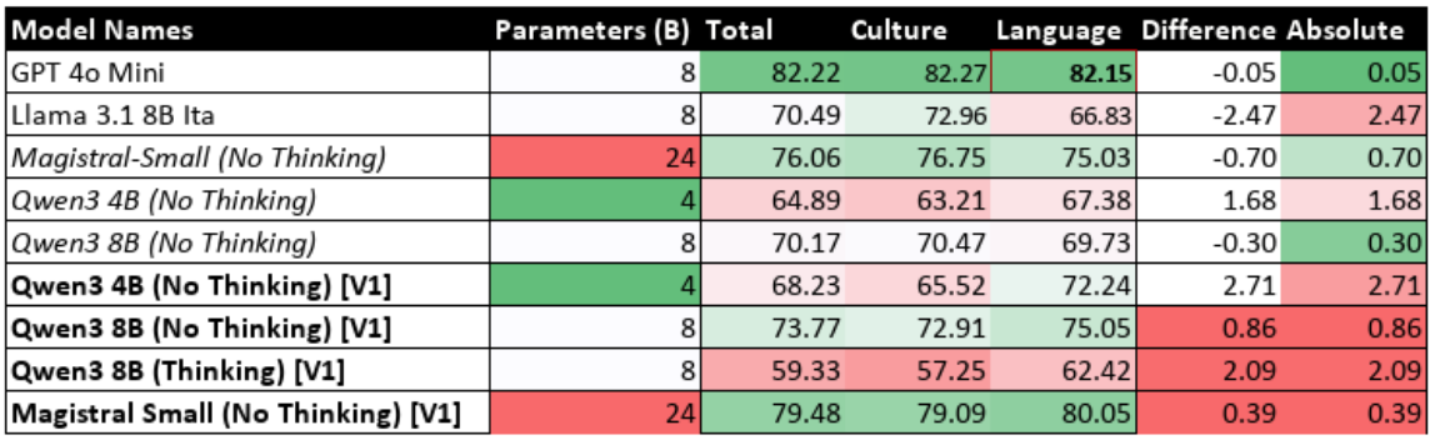
Table 9.6: Performance of Fine-Tuned Models with Reasoning Enabled (Iteration 1)
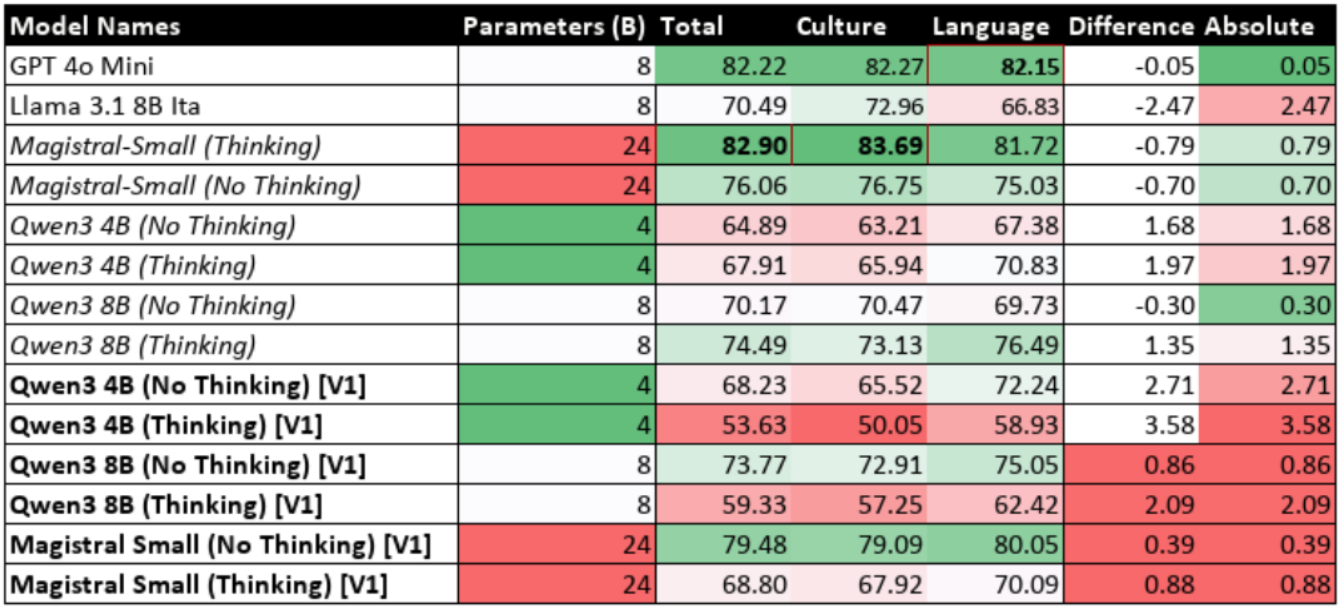
Table 9.7: Performance of Fine-Tuned Models with Reasoning Disabled (Iteration 2)
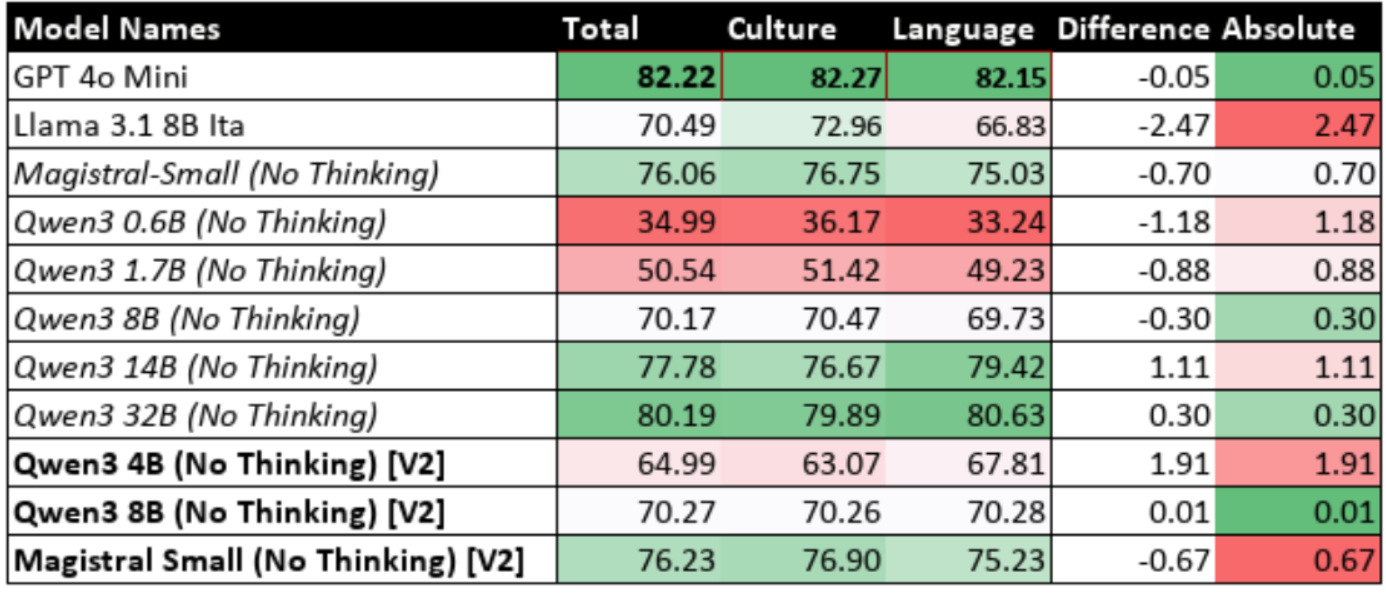
Table 9.8: Performance of Fine-Tuned Models with Reasoning Enabled (Iteration 2)
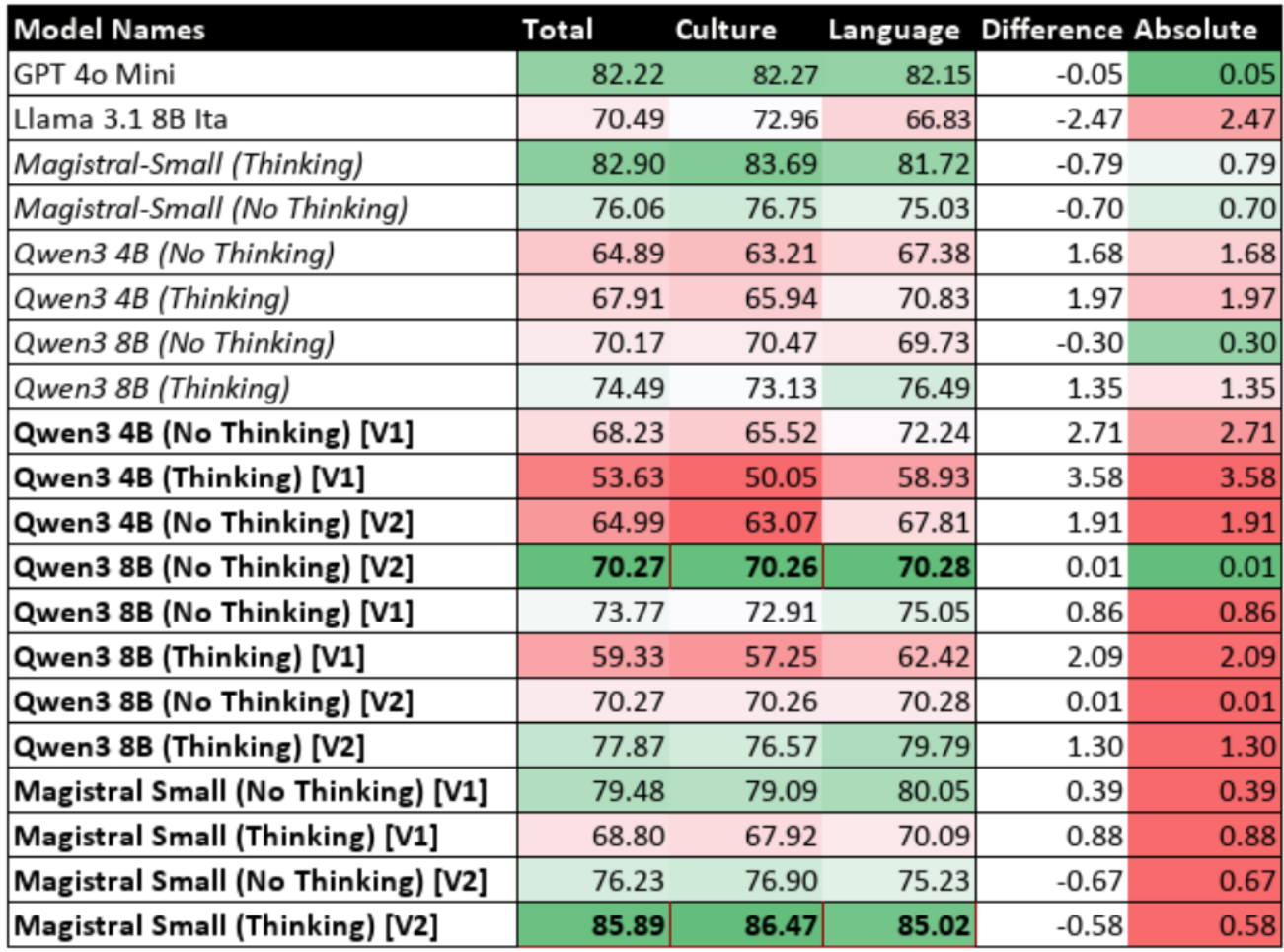
Table 9.9: Performance of Fine-Tuned Models with Reasoning Disabled (Iteration 3)
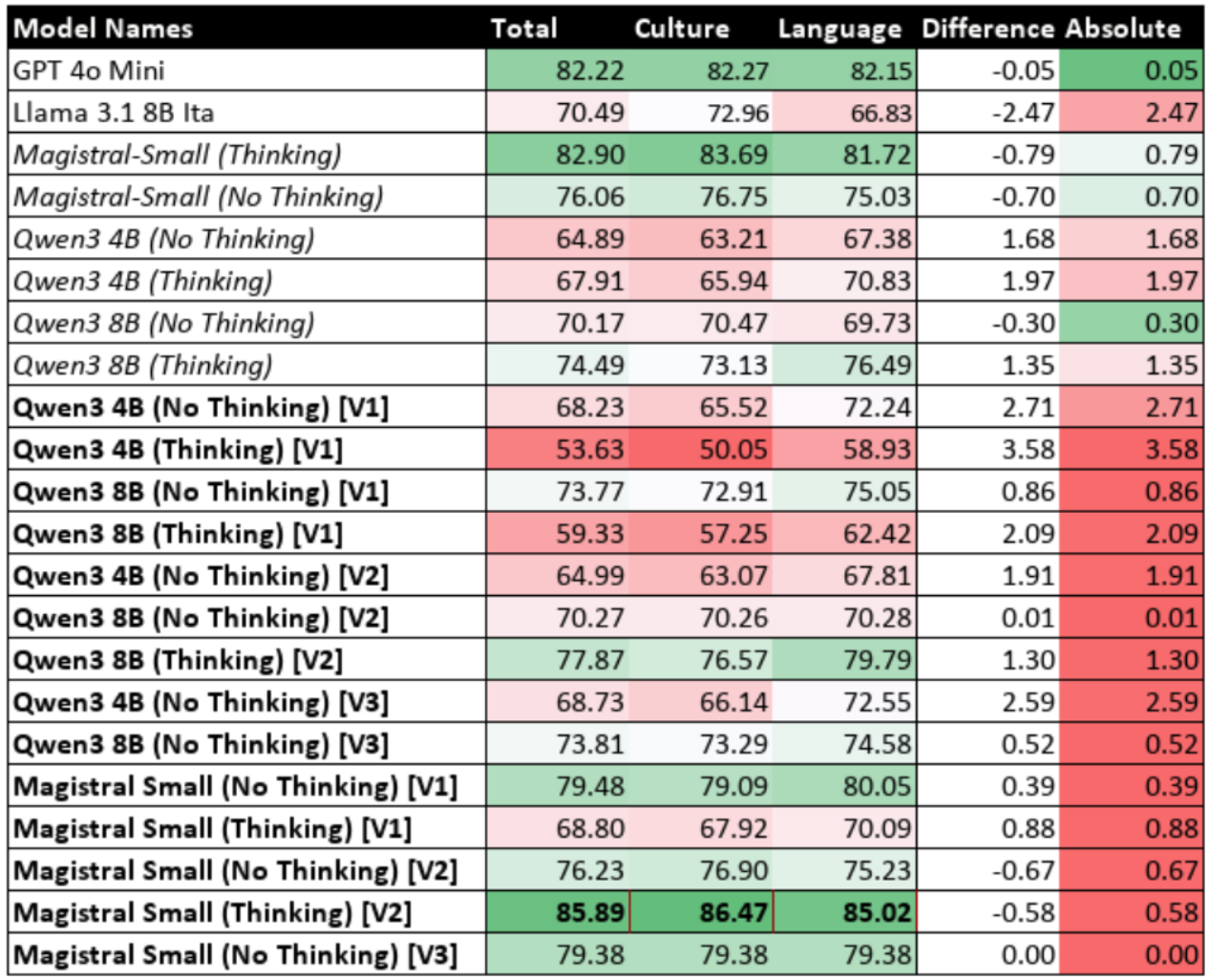
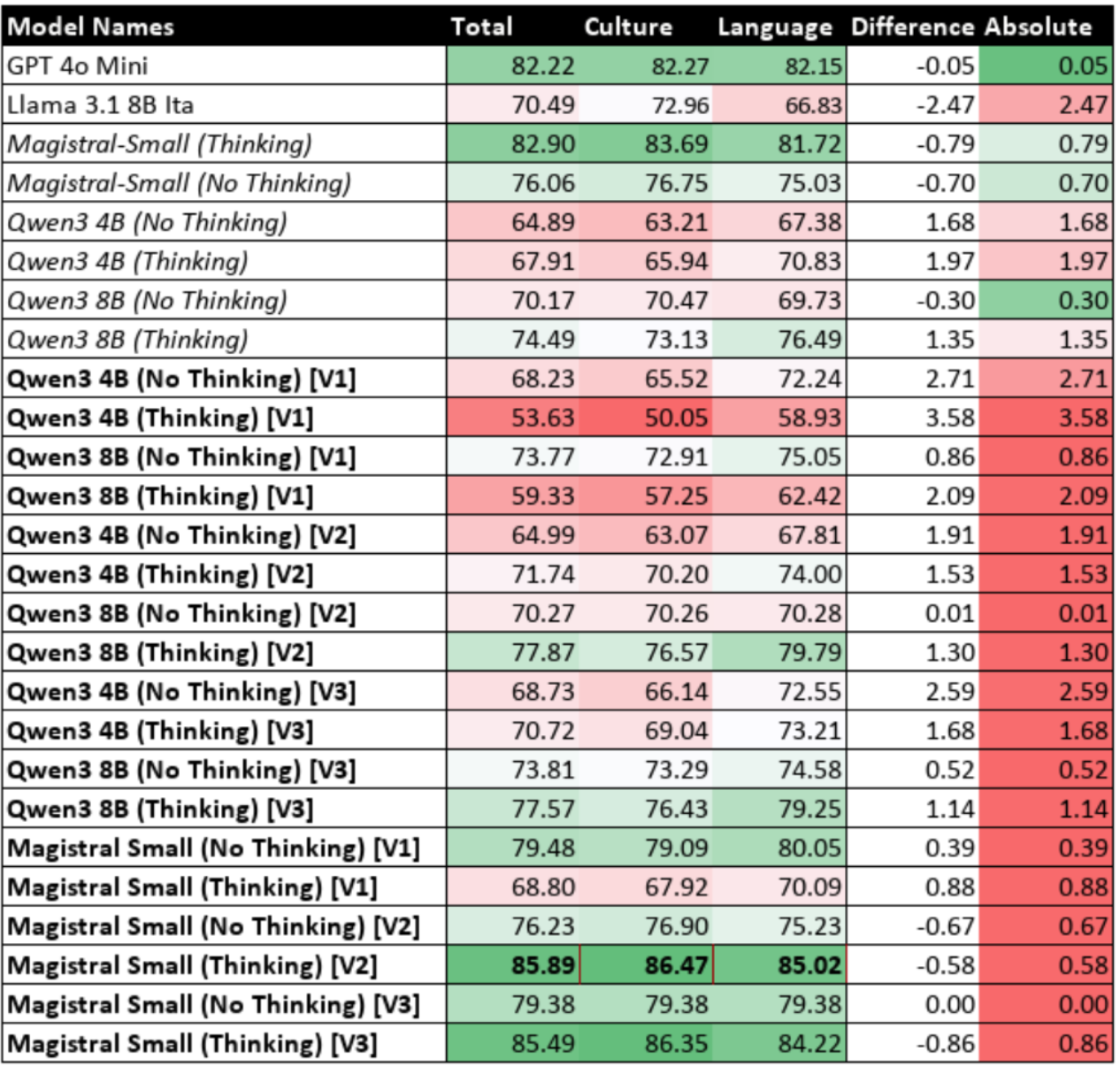
Table 9.10: Performance of Fine-Tuned Models with Reasoning Enabled (Iteration 3)
List of Figures
Figure 6.1: Experimental Pipeline Architecture
Figure 6.2: Fine-Tuning and Evaluation Cycle
Figure 6.3: Standard Pipeline
Figure 6.4: Synthetic Only Test Pipeline
Figure 6.5: Hybrid Training Pipeline
`
Figure 9.1: Performance Difference Between Reasoning and No-Reasoning States
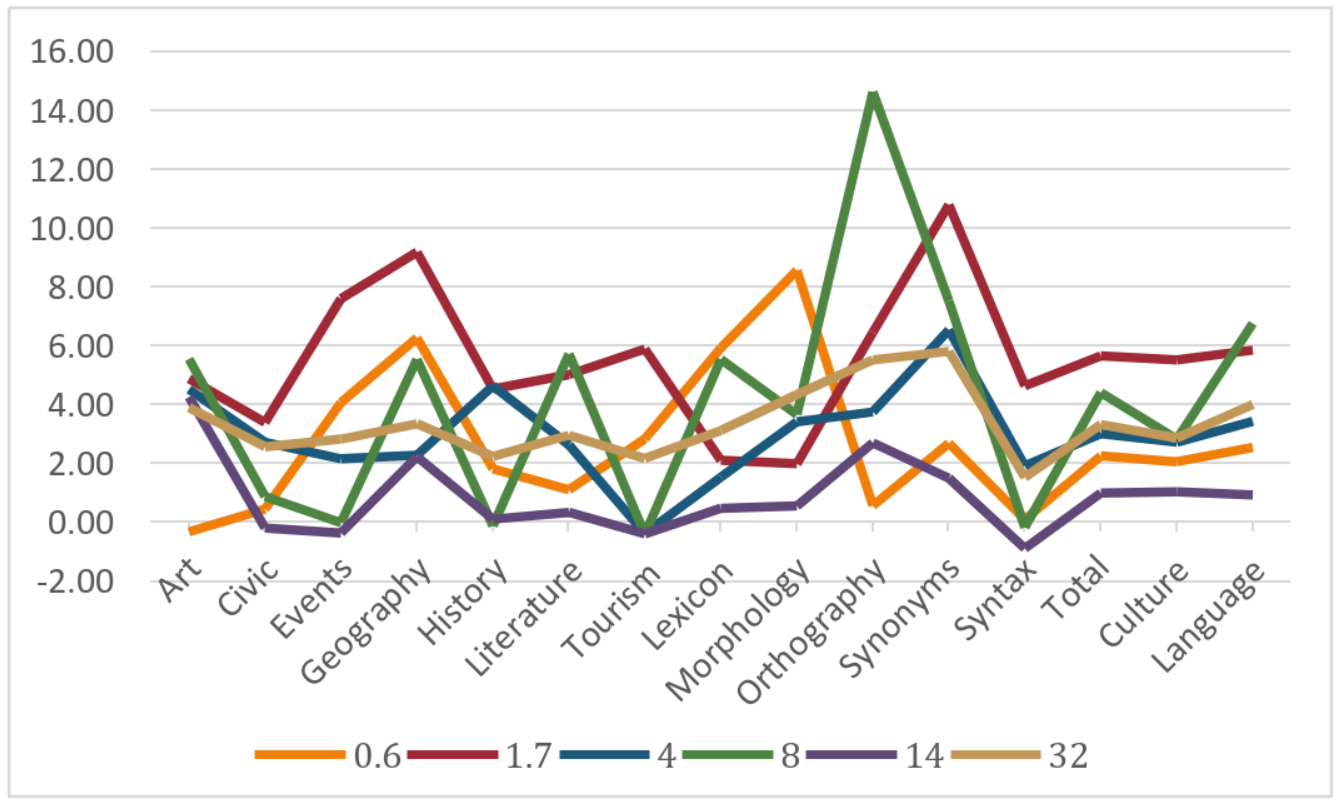
Figure 9.2: Average Difference Across Models for Reasoning & Non-Reasoning
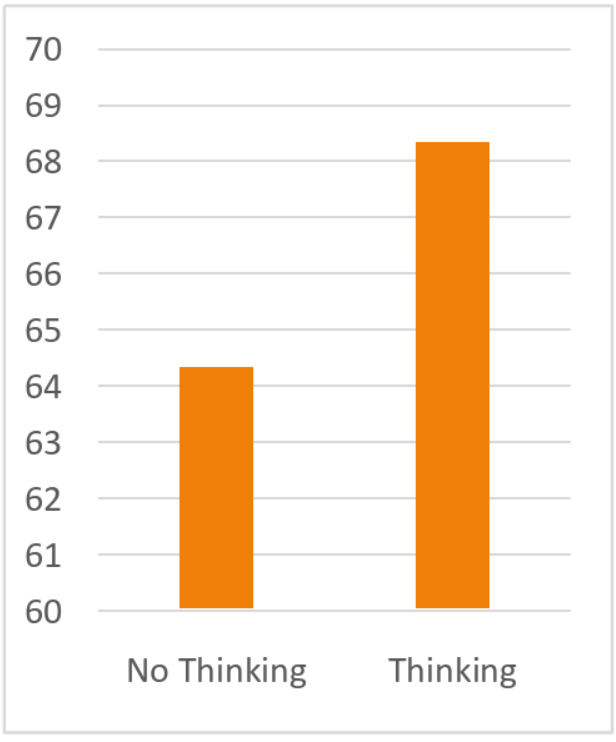
Figure 9.3: Accuracies for Reasoning & Non-Reasoning Based on Scale
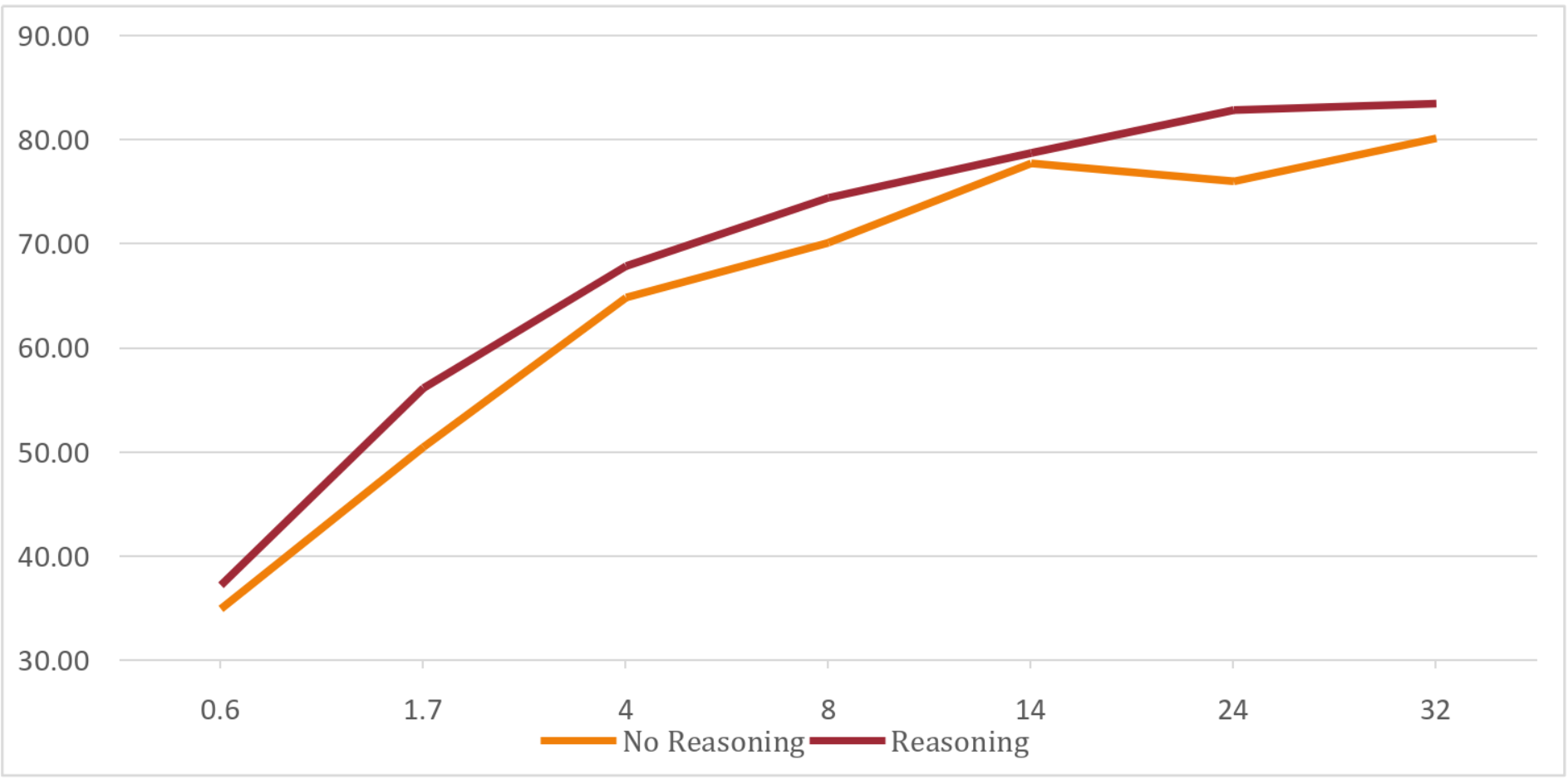
Figure 9.4: Summary of Model Accuracy Against Reference Models, Base Models and Fine-Tuned Models
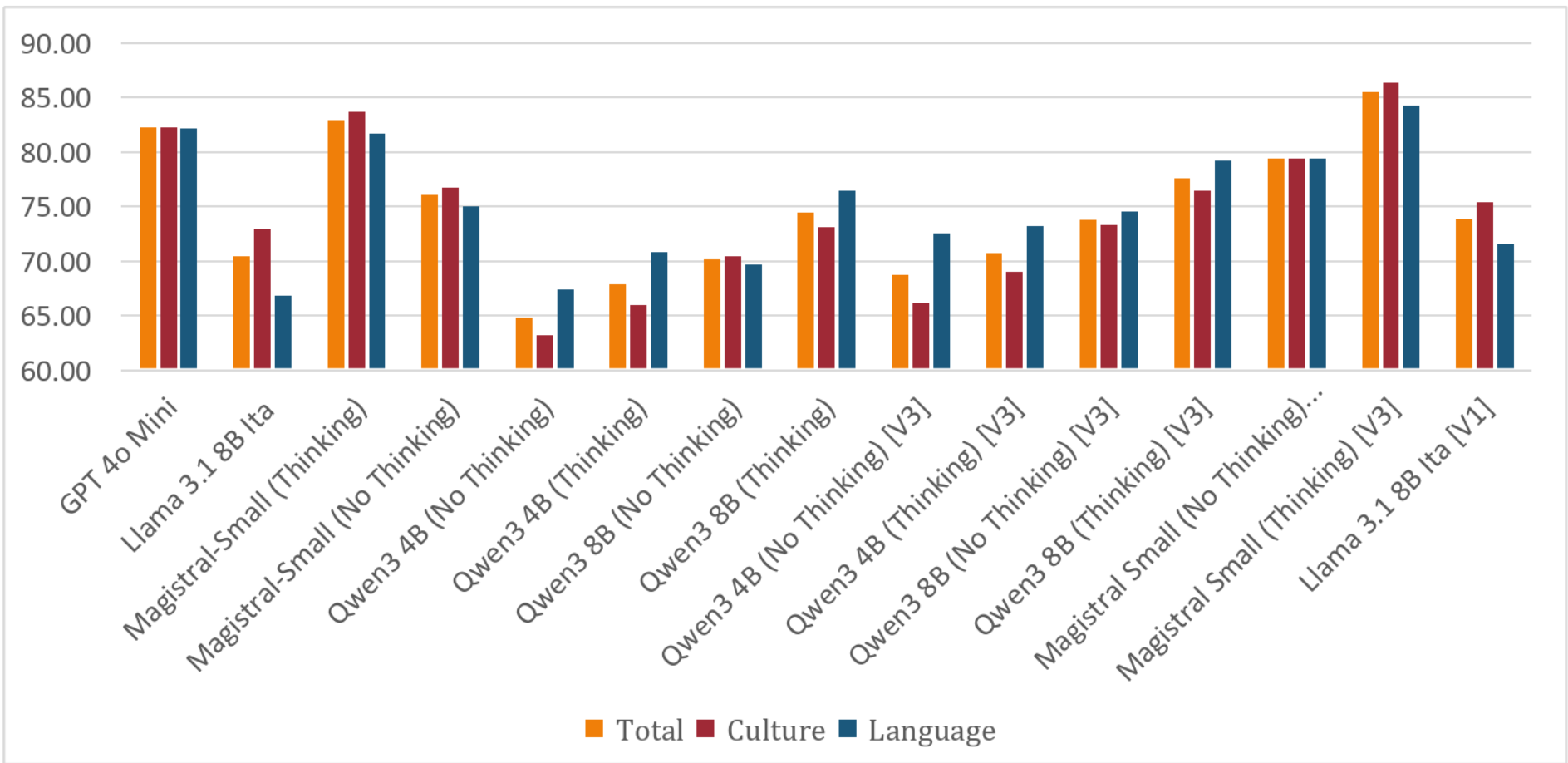
1 - Introduction
1.1 - Background & Motivation
Recent advancements in Large Language Models (LLMs) have led to their widespread integration into global digital services, from powering conversational search engines to automating customer support. For these models to be fair and effective, they must be culturally aware. However, current research shows a strong bias towards English and Western cultures, slowing adoption in other regions due to significant linguistic and cultural barriers [Seveso et al., 2025]. This has led to the development of native-language benchmarks, such as ITALIC for Italian, which provides a more authentic assessment of a model's capabilities.
This project focuses specifically on smaller LLMs, as their efficiency makes them critical for real-world deployment. Unlike their larger counterparts, which require substantial computational resources, smaller models are affordable for most companies to train and deploy in applications like customer service agents. For these tools to be effective, they must be linguistically aligned to sound natural. Similarly, for home users running assistants locally for everyday tasks, cultural and linguistic alignment is essential for the technology to feel genuinely helpful.
1.2 - Research Problem
However, analysis using the ITALIC benchmark has revealed a critical and consistent discrepancy in these smaller models: they perform significantly better on tasks requiring general cultural knowledge than on those demanding a deep understanding of language-specific rules. The benchmark shows an average model accuracy of 75.03% on cultural tasks, which drops to just 63.12% on linguistic tasks. This performance gap is particularly wide in smaller, more efficient models, with foundational language skills like morphology and orthography being the weakest areas. This highlights a fundamental challenge: cultural knowledge does not guarantee linguistic competence. Crucially, existing research has focused on standard LLMs, leaving the potential for newer, reasoning-capable models to address this linguistic gap largely unexplored.
1.3 - Aims & Hypotheses
This project directly addresses this performance gap in smaller LLMs for the Italian language, guided by two central hypotheses. The first is that modern LLMs with reasoning capabilities may be better equipped to handle complex linguistic problems. This study makes a novel contribution by applying these reasoning methods to linguistics. Such models are typically used for tasks like mathematics and programming; their potential for language has been largely unexplored. However, activating these reasoning processes is computationally expensive and introduces delay, which is often impractical for real-time applications. Users interacting with customer service agents, for example, cannot wait for a lengthy thought process just for a grammatically correct response. This would also be expensive for businesses as more compute is being used.
This leads to the second hypothesis. While reasoning is effective, it is also slow and computationally expensive. The project therefore explored fine-tuning to improve the models' faster, non-reasoning mode. However, this revealed a critical trade-off: regular fine-tuning successfully improved linguistic skills but destroyed the models' ability to reason. The second hypothesis is that a novel hybrid training approach can solve this problem. This method uses LoRA and mixes a standard dataset with synthetically generated Chain-of-Thought (CoT) examples from the target model itself. The goal is to boost linguistic performance in the efficient non-reasoning mode, while also preserving the model's core reasoning abilities. This report will detail the investigation into these hypotheses, from a review of the relevant literature to the final analysis of the results and a discussion of their implications.
2 - Literature Survey
2.1 - Cultural Alignment in Large Language Models (LLMs)
Recent research highlights significant challenges in achieving cultural alignment in LLMs. Studies consistently show that current LLMs exhibit strong Anglocentric and Western-centric biases. They perform substantially better on English-language tasks while struggling with culturally-specific knowledge in underrepresented languages [Pawar et al., 2024; Rao et al., 2024]. This cultural misalignment stems primarily from training data composition. English and Western sources dominate these datasets, creating a risk of "cultural homogenisation" where anglocentric models become the default [Seveso et al., 2025].
The problem extends beyond simple translation. Even perfectly translated benchmarks can be culturally biased. For instance, an analysis of the widely-used MMLU benchmark found that a significant portion of questions requires culturally sensitive knowledge, with the vast majority of these being specific to North America or Europe [Singha et al., 2025]. This creates an unfair evaluation standard, as models are penalised for not mastering Western-centric concepts [Moroni et al., 2024; Seveso et al., 2025].
This has led to a key finding: a fundamental discrepancy exists between cultural knowledge and linguistic understanding in LLMs. While LLMs may possess broad cultural knowledge, this often fails to translate into a deep comprehension of language-specific rules, particularly in morphologically rich languages like Italian [Rao et al., 2024]. This gap becomes especially pronounced in smaller models, where linguistic tasks such as morphology and orthography present greater challenges than general cultural knowledge.
2.2 - Italian Language Model Research & Benchmarking
The Italian NLP community has historically lacked comprehensive evaluation benchmarks compared to English. Early Italian benchmarks focused primarily on classification-based tasks such as sentiment analysis and hate speech detection, failing to assess higher-level capabilities like commonsense reasoning [Basile et al., 2023; Lai et al., 2023]. This limitation has hindered the systematic evaluation of LLM performance in Italian cultural and linguistic contexts. In response, a new generation of more comprehensive, native Italian benchmarks has been developed. These include collaborative efforts like CALAMITA and evaluation suites such as ItaEval, which cover a wide range of tasks from hate speech to gender-neutral rephrasing [Attanasio et al., 2024a; Attanasio et al., 2024b]. However, many of these initiatives either combine multiple smaller datasets, which can complicate standardised testing, or rely on machine-translated content from English sources [Moroni et al., 2024].
The introduction of ITALIC [Seveso et al., 2025] represents a significant advancement. It was chosen for this project because it provides a single, comprehensive benchmark built from authentic, native Italian materials. It comprises 10,000 multiple-choice questions derived from Italian public examination materials, spanning 12 domains across two main categories: Culture and Commonsense (encompassing history, geography, literature, and civic knowledge) and Language Capability (covering syntax, morphology, orthography, and lexicon). Unlike benchmarks that rely on translated content, ITALIC's use of native sources provides a more authentic cultural and linguistic evaluation.
ITALIC's comprehensive evaluation of 17 models revealed systematic performance gaps [Seveso et al., 2025]. Models consistently performed better on Culture and Commonsense tasks (average 75.03%) compared to Language Capability tasks (average 63.12%). Morphology emerged as the most challenging domain (55.99% average accuracy), followed by orthography (62.09% average accuracy). This pattern held across both proprietary and open-weights models, indicating fundamental limitations in linguistic understanding rather than model-specific issues. Additionally, open-weights models tend to perform worse compared to their proprietary counterparts, with GPT-4o-Mini scoring 82.22% whereas Llama 3.1 8B Ita (fine-tuned on Italian) scores 70.49% and the standard Llama 3.1 8B scores 66.38%.
2.3 - Performance Characteristics of Smaller LLMs
Smaller-scale LLMs (5-35B parameters) face particular challenges in cultural and linguistic alignment. The ITALIC benchmark demonstrates clear scaling effects, with larger models generally outperforming smaller counterparts with Llama 3.1 405B scoring 88.89% whereas the smaller Llama 3.1 8B only scores 66.38% [Seveso et al., 2025]. However, the performance gap varies significantly across domains, with linguistic tasks showing steeper scaling curves than cultural knowledge tasks; this is proven by the difference between Culture and Common sense and Language Understanding, where the discrepancy between Llama 3.1 405B is 4.98% but the discrepancy for Llama 3.1 8B is 9.72%.
Among smaller models, the Llama 3.1 8B provides instructive examples. The base multilingual Llama 3.1 8B achieved 66.38% overall accuracy on ITALIC, with notable weaknesses in morphology (40.00%) and orthography (49.33%) [Seveso et al., 2025]. The Italian-specific fine-tuned variant (Llama 3.1 8B Ita) showed modest improvements to 70.49% (+4.11%) overall, with the largest gains in Language Capability tasks (+6.25 percentage points) compared to Culture and Commonsense (+2.66 percentage points).
More specifically, Llama 3.1 8B Ita achieved 72.96% in Culture and Commonsense but only 66.83% in Language Capability [Seveso et al., 2025]. This reveals a substantial performance gap. After fine-tuning, the improvement for Culture and Commonsense was only 2.66%, while the improvement for Language Capability was a much larger 6.25%. This indicates significant potential for further enhancement in linguistic tasks. This pattern suggests that Culture and Commonsense knowledge is already well-established through cross-lingual training. Language Capability, however, requires more targeted native language training. Despite the larger improvement, Language Capability performance remains substantially below Culture and Commonsense levels (6.13% difference) which highlights the persistent challenge of linguistic understanding.
Morphology represents the most challenging domain across both Llama 3.1 8B variants, with the base model scoring only 40.00% and the Italian fine-tuned version achieving 52.14% [Seveso et al., 2025]. Orthography was the second weakest area, with the base model scoring 49.33% and increasing to 53.04% after fine-tuning. In comparison, syntax scores were slightly higher, starting at 50.46% for the base model and rising to 53.65% for the fine-tuned model. Collectively, these are the lowest scores across all ITALIC domains, emphasising the particular difficulty of foundational linguistic understanding in Italian.
2.4 - Comparing Multilingual & Monolingual Model Performance
Recent research has established clear performance hierarchies between different model types. According to both ITALIC findings [Seveso et al., 2025] and complementary studies [Fan et al., 2025, Polignano et al., 2023], multilingual models consistently outperform monolingual Italian models, particularly when the monolingual models are trained from scratch rather than fine-tuned from existing multilingual foundations.
This pattern is evident in ITALIC results, where ground-up Italian models like Minerva 7B (41.55% overall) and Modello Italia 9B (50.53% overall) significantly underperformed multilingual alternatives [Seveso et al., 2025]. The superior performance of multilingual models stems from their ability to leverage cross-lingual knowledge transfer, where concepts learnt through one language can be applied when responding in another language [Fan et al., 2025; Polignano et al., 2023].
The exception to this pattern involves models fine-tuned from multilingual foundations rather than trained from scratch. Llama 3.1 8B Ita demonstrates this advantage, outperforming most ground-up Italian models whilst maintaining access to multilingual knowledge representations [Seveso et al., 2025]. This clearly highlights that the optimal approach to achieving cultural alignment is by building upon the foundations of multi-lingual models rather than building mono-lingual models from scratch.
2.5 - Identified Gaps
2.5.1 - Discrepancy Between Cultural & Linguistics in Smaller Models
A significant finding from the ITALIC benchmark is the performance gap between tasks requiring cultural knowledge and those requiring linguistic understanding. This discrepancy is particularly pronounced in smaller-scale, open-weight models [Seveso et al., 2025]. While large-scale proprietary models like Claude 3.5 Sonnet exhibit a minimal gap (1.39 percentage points between Culture and Language scores), this difference becomes substantially larger in smaller and/or open models. For example, Llama 3.1 405B has a discrepancy of 4.98%, which widens to a significant 9.72% in Llama 3.1 8B. This trend demonstrates that as model size decreases, the relative weakness in handling the structural and grammatical rules of a language becomes more acute compared to performance on cultural knowledge. This highlights a key research gap: understanding why smaller models struggle disproportionately with linguistic tasks and developing targeted interventions to close this specific performance gap.
2.5.2 - Limited Analysis of Reasoning Model Benefits
The current literature, including the foundational ITALIC benchmark study, has not yet evaluated the performance of modern reasoning-capable models on Italian cultural and linguistic tasks. The models assessed in the paper are primarily standard LLMs, and there is no analysis of newer architectures that are explicitly designed to "think step by step" before generating an answer. These include proprietary models (like GPT-4o, Claude 4 and GPT-o3) and open-weight alternatives (like DeepSeek R1, Magistral, and Qwen3). Chain-of-Thought (CoT) encourage a model to break down a question into intermediate steps, a process that could be beneficial for navigating the complexities of Italian linguistics and to use the existing knowledge more effectively. It is plausible that activating a model's reasoning capabilities could, on its own, improve performance on difficult linguistic tasks by allowing for more deliberate processing, thereby narrowing the performance gap between cultural and linguistic understanding without the need for extensive fine-tuning. This project aims to directly investigate this hypothesis by systematically benchmarking such models and of various sizes, an area currently unexplored in the context of Italian cultural alignment.
2.5.3 - Weaknesses in Linguistic Capabilities
The ITALIC benchmark reveals that morphology, orthography, and syntax are consistently the weakest areas for LLMs in Italian [Seveso et al., 2025]. These findings are consistent with broader research, which shows LLMs struggle with morphologically complex languages and can suffer a drop in language understanding when working in Italian, even if their core reasoning skills remain [Ismayilzada et al., 2025; Puccetti et al., 2025]. Morphology consistently emerges as the most difficult domain for the models. The average accuracy across all tested models in morphology is only 55.99%. For smaller models like the base Llama 3.1 8B, the performance is even lower at just 40.00%. Orthography is the second most challenging domain, with an average accuracy of 62.09% across all models in the ITALIC benchmark. Again, smaller models struggle significantly in this area. Syntax is the third area of notable weakness. While the average accuracy is slightly higher at 64.37%, it still lags behind performance on tasks requiring cultural knowledge. The lack of effective, targeted methods to improve these specific linguistic abilities in Italian LLMs highlights a clear and important research gap.
3 - Background Theories
3.1 - Transformer Architecture
The Transformer architecture [Vaswani et al., 2017] forms the foundational backbone for virtually all modern LLMs, including those used in this project. It revolutionised the field by replacing the sequential processing of older models like Recurrent Neural Networks (RNNs). RNNs struggled with slow, token-by-token computation and had difficulty capturing long-range context in text. The Transformer overcame these limitations by abandoning recurrence in favour of a fully parallelisable mechanism known as self-attention [Vaswani et al., 2017].
The self-attention mechanism allows the model to weigh the importance of different words in a sentence simultaneously when processing a single word. This is achieved through several key components. Each word is represented by three vectors: a Query (Q), representing the current word's request for context; a Key (K), which acts as a label for other words; and a Value (V), containing the word's actual information. The attention score, which signifies relevance, is calculated by taking the dot product of the Query with all other Keys. This process is captured by the equation:
This mechanism allows the model to process entire sequences in parallel, drawing information from the entire sequence at once [Vaswani et al., 2017].
The Transformer also employs Multi-Head Attention, which runs multiple self-attention processes in parallel. Each of these "heads" learns to focus on different types of relationships in the text, such as syntactic dependencies or semantic similarities. The outputs are then combined, resulting in a much richer and more nuanced understanding of the language [Vaswani et al., 2017].
To maintain sequential information, the Transformer injects positional encoding vectors into the input. These provide crucial information about each token's position in the sequence [Vaswani et al., 2017].
The architecture also includes Feed-Forward Networks for additional non-linearity. To enable deep training, the architecture uses residual connections and layer normalisation, which stabilises the learning process and prevents gradients from vanishing [Vaswani et al., 2017].
3.1.1 - Architectural Evolution & Specialisation
While the original Transformer was designed with an encoder-decoder structure for machine translation, its modularity spurred an architectural evolution. This led to specialised variants that underpin most modern LLMs:
Encoder-only models, such as BERT, use the Transformer's encoder stack to pre-train deep bidirectional representations. This makes them exceptionally powerful for Natural Language Understanding (NLU) tasks where a deep comprehension of the full context is required [Devlin et al., 2019].
Decoder-only models, such as the GPT series, use the Transformer's decoder stack. These models are autoregressive, generating text one token at a time based on previously generated tokens. This makes them highly effective for Natural Language Generation (NLG) tasks [Radford et al., 2018]. The models evaluated in this project (including Llama, Mistral/Magistral, and Qwen) are all descendants of this decoder-only lineage.
3.1.2 - Comparison with Pre-Transformer Neural Architectures
Before the Transformer, NLP was dominated by architectures with significant limitations. RNNs, including more advanced variants like LSTMs and GRUs, processed text sequentially, which created a computational bottleneck that hindered parallelism and made it difficult to capture long-range dependencies [Hochreiter & Schmidhuber, 1997; Chung et al., 2014]. CNNs offered parallelism but could only capture context within a limited local window, struggling with variable-length relationships in text [Kim, 2014]. The Transformer superseded these models because its self-attention mechanism processes all tokens in parallel, allowing information to flow globally across the entire sequence in a single step. This solved both the sequential bottleneck of RNNs and the limited receptive field of CNNs, enabling the massive scale and emergent capabilities of modern LLMs.
3.1.3 - Recent Progress in Large Language Models
The last five years have seen LLMs scale dramatically, with increased size and innovations like instruction-tuning and Reinforcement Learning from Human Feedback (RLHF) unlocking new capabilities [Brown et al., 2020]. However, the frontier of LLM development has shifted from pure scale to enhancing specific cognitive capabilities.
This has led to a new generation of models explicitly architected for advanced reasoning, such as GPT-4o, Claude 4, and Gemini 2.5 Pro [Bubeck et al., 2023]. A key innovation in this space is the development of hybrid reasoning models, which can operate in a fast, standard mode for simple queries or switch to a more computationally intensive "thinking" mode for complex problems. Investigating whether these advanced reasoning techniques can be leveraged to improve performance on complex linguistic tasks is the central question of this project's first hypothesis. The following section delves into the specific techniques that enable this advanced reasoning.
3.2 - Reasoning Models
Standard LLMs built on the Transformer architecture are trained to predict the next word in a sequence. While this makes them proficient at language tasks, it is insufficient for problems requiring logical deduction. A deep understanding of these techniques is fundamental to this project's first hypothesis: that the latent reasoning capabilities of modern LLMs can be leveraged to close the performance gap between cultural and linguistic understanding. For tasks in mathematics or commonsense reasoning, simply predicting the most statistically likely word often fails to produce a correct solution. This limitation is shown by "flat scaling curves," where simply increasing a model's size does not significantly improve performance on complex reasoning without a fundamental shift in methodology [Wei et al., 2022].
The ability for complex reasoning is not an automatic result of scale; it must be deliberately prompted or engineered. In this context, "reasoning" is the ability to break down a problem into a series of intermediate steps that logically lead to a conclusion. The introduction of CoT prompting was a foundational shift, demonstrating that the latent reasoning abilities of large models could be unlocked by guiding them to externalise their problem-solving process [Wei et al., 2022]. This success has led to the development of specialised reasoning models that are explicitly trained and architected for complex reasoning.
3.2.1 - Foundational Techniques for Eliciting Reasoning
CoT prompting works by encouraging a model to generate a sequence of intermediate steps before the final answer. This reframes the task from a single, difficult inference to a series of simpler, incremental predictions. Instead of a large cognitive leap, the model performs a sequence of more manageable next-token predictions, effectively allocating more computation to the problem by generating a longer thought process. This is typically implemented via few-shot CoT, where the model is given examples of solved problems, or zero-shot CoT, where a simple instruction like "Think step by step" is used.
A critical finding is that CoT is an emergent property of model scale; its benefits only appear in models with around 100 billion parameters or more and can degrade the performance of smaller models [Wei et al., 2022]. However, a single reasoning chain is brittle, as one early error can corrupt the entire output. To address this, self-consistency was introduced as a decoding strategy [Wang et al., 2022]. It generates multiple, diverse reasoning paths for the same problem and determines the final answer by a majority vote. This ensemble-like approach significantly improves robustness, yielding gains of +17.9% on the GSM8K benchmark, but at the cost of increased computation.
3.2.2 - Advanced Reasoning Frameworks & Strategies
The linear, step-by-step nature of CoT is ineffective for tasks that require planning or exploration. Tree of Thoughts (ToT) provides a more powerful framework by modelling problem-solving as a search through a tree of possibilities, which is closer to human cognition [Yao et al., 2023]. In the ToT framework, an LLM is used to generate multiple potential next steps ("thoughts"), a checker module evaluates their validity and promise, and a controller manages the search process using algorithms like breadth-first or depth-first search.
The most significant feature of ToT is its ability to backtrack. If a path of reasoning is found to be unpromising, the controller can discard that branch and explore an alternative from a previous state. This capacity for systematic exploration and error correction allows ToT to solve complex planning problems, such as the Game of 24, that are often intractable for linear CoT methods [Yao et al., 2023]. This represents a move from simple generation to a more structured and robust problem-solving paradigm.
3.2.3 - Mitigating Inference Time & Cost
While early reasoning techniques focused on accuracy, their high latency and token consumption are barriers to practical use. This has driven innovation toward more efficient reasoning.
One key technique is Chain of Draft (CoD), which challenges the assumption that more verbose reasoning is better. Inspired by how humans often jot down only key intermediate results, CoD prompts the model to generate minimalistic yet informative reasoning steps. This approach significantly reduces latency and cost, often with no loss in accuracy [Tian et al., 2025].
Another strategy, Confidence-Informed Self-Consistency (CISC), targets the high cost of standard self-consistency. After generating each reasoning path, the model is prompted to evaluate its confidence in that path's correctness. The final answer is then determined by a weighted majority vote, giving more influence to high-confidence paths. This allows the system to converge on the correct answer with over 40% fewer reasoning paths, making the technique more practical and scalable [Taubenfeld et al., 2025].
3.2.4 - Training & Architectures
The latest reasoning models are explicitly trained for this capability, moving beyond prompting alone. While Supervised Fine-Tuning (SFT) on reasoning examples is effective, it is limited by the quality of static datasets. Reinforcement Learning (RL) offers a more scalable paradigm where the model learns through trial-and-error, receiving feedback on its generated reasoning. A key innovation is Reinforcement Learning from Verifiable Rewards (RLVR), which uses a reward signal from a deterministic, objective verifier, such as checking a maths answer for correctness or running code against unit tests. This provides a clear, ground-truth-aligned signal that allows the model to autonomously discover correct reasoning paths [Guo et al., 2025].
To implement this efficiently, models like DeepSeek and Magistral use algorithms such as Group Relative Policy Optimisation (GRPO). GRPO streamlines RL by removing the need for a separate value model, instead calculating the advantage of a response based on its reward relative to the average reward of other sampled responses [Mistral-AI, Rastogi, et al., 2025]. The DeepSeek R1 model demonstrated that a pure RLVR approach could lead to the autonomous emergence of sophisticated behaviors like self-verification, boosting its AIME benchmark score from 15.6% to 71.0% [Guo et al., 2025]. Similarly, Mistral's Magistral was trained with RL to increase its AIME score by 50% and was specifically designed for multilingual reasoning by including translated problems and a language consistency reward in its training data [Mistral-AI, Rastogi, et al., 2025].
Alongside training innovations, new architectures allow models to dynamically allocate computation at inference time. Google's Gemini 2.5 Pro has an integrated "thinking process" that can perform tens of thousands of extra forward passes to explore a problem, with the amount of thinking calibrated to the task's complexity [Google AI, 2025]. Anthropic's Claude 4 features distinct operational modes: a standard mode for fast responses and an "extended thinking mode" for deep reasoning, which can also integrate external tools like a code interpreter [Anthropic, 2025]. These architectures enable a more intelligent allocation of resources, balancing performance with efficiency.
3.2.5 - Multilingual Reasoning Capabilities
As LLMs are deployed globally, their ability to reason across multiple languages is critical. Models like the Qwen2 series and Mistral's Magistral have been explicitly trained for this [Qwen Team, 2024a]. Magistral incorporated translated mathematics and coding problems into its RL training data and used a language consistency reward to ensure it could reason natively in languages like French, Spanish, and German [Mistral-AI, Rastogi, et al., 2025].
Despite these efforts, a performance gap persists between English and other languages. The Magistral Medium model, for instance, sees its performance on translated versions of the AIME benchmark drop by 4.3% to 9.9% compared to English [Mistral-AI, Rastogi, et al., 2025]. This suggests that reasoning is not a purely abstract, language-agnostic skill in current LLMs. Instead, it appears deeply connected to the specific linguistic patterns in the training data, and the learned associations between phrasing and logical operations in one language do not always transfer perfectly to others [Ahuja et al., 2025].
3.2.6 - Reasoning vs. Non-Reasoning Models
Reasoning models offer clear advantages for complex problems. They are more accurate and reliable than standard models. Their step-by-step output also provides a window into their process. This makes it easier for users to check the logic, spot errors, and build trust in the final answer. In contrast, normal models provide direct answers which is faster but offers no justification [AiSDR, 2025].
However, these benefits come with significant trade-offs. Reasoning models are slower and more expensive to run because generating long thought processes uses more computation. The "interpretability" they offer must also be viewed carefully. The reasoning path a model shows might be a convincing story created after the answer is found, not a true reflection of how it solved the problem [Turpin et al., 2024]. The pursuit of truly verifiable and causally-grounded reasoning (ensuring the logic is sound and factually correct) remains a key challenge. A deeper issue is the trade-off between specialisation and generalisation. Training a model to excel at reasoning can make it worse at other tasks, like following conversational instructions [Seveso et al., 2025]. This suggests that AI "intelligence" is not a single quality but a collection of skills that can compete with each other. This is why hybrid models like Claude, Qwen and Magistral (which can switch between a fast, general mode and a slow, reasoning mode) are being developed. They aim to provide the best of both worlds.
3.3 - Low Rank Adaptation (LoRA)
3.3.1 - PEFT
Traditional method, Full Fine-Tuning (FFT), involves updating all of a model's parameters on a new, task-specific dataset. While effective, this approach has become increasingly impractical for modern LLMs, which can have billions of parameters (or even hundreds of billions). The computational cost, memory requirements, and storage demands of FFT are prohibitive for most researchers and organisations, as each fine-tuned model is a complete, multi-gigabyte copy of the original [Hu et al., 2022]. Furthermore, FFT carries a significant risk of "catastrophic forgetting," where the model loses valuable general-purpose knowledge acquired during pre-training as it learns the new task [Kirkpatrick et al., 2017].
(PEFT). The core principle of PEFT is to freeze the vast majority (often over 99%) of the pre-trained model's parameters and only train a small number of new or existing parameters. This dramatically reduces computational and storage costs, making LLM customisation more accessible while often achieving performance comparable to FFT [Hu et al., 2022]. This technique is central to the project's second phase, providing the parameter-efficient methodology required to test the hypothesis that linguistic improvements can be achieved without catastrophic forgetting.
3.3.2 - LoRA
LoRA is a particularly elegant and effective PEFT technique [Hu et al., 2022]. It is based on the hypothesis that the change in a model's weights during adaptation to a new task has a low "intrinsic rank" [Hu et al., 2022]. This means the adjustments required to specialise a model are not complex and diffuse but are concentrated and can be represented efficiently in a lower-dimensional subspace.
3.3.3 - LoRA Mechanism
LoRA injects trainable rank decomposition matrices into each layer of the Transformer architecture, creating a parallel module. This module represents the change in weights (ΔW) as the product of two much smaller, "low-rank" matrices: A and B. During training, the original weight matrix remains frozen and does not have its gradients updated. Only the parameters of the newly introduced matrices A and B are trained [Hu et al., 2022].
The forward pass is modified to combine the output from the original frozen path and the new, trained path:
This approach is highly parameter-efficient. For example, adapting a 1000×1000 weight matrix (1 million parameters) using LoRA with a rank of would only require training parameters, a reduction of over 99% [Hu et al., 2022].
3.3.4 - Advantages of LoRA
Once training is complete, the learned matrices can be mathematically merged with the original weights by calculating . The resulting model has the exact same architecture and parameter count as the original, making it highly efficient for deployment [Hu et al., 2022].
This ability to merge adapters is a crucial factor for this project [Hu et al., 2022]. This allows for the creation of many small, task-specific "adapters" (often just a few megabytes in size) that can be swapped out to modify the model's behaviour without altering the base model. This is orders of magnitude more efficient in terms of computational cost, memory usage, and storage [Hu et al., 2022]. By freezing the base model, it also serves as a strong regulariser that mitigates catastrophic forgetting [Hu et al., 2022], while often matching or exceeding FFT's performance on a wide range of tasks [Long et al., 2024]. LoRA avoids the inference latency added by methods like Adapter Tuning [Houlsby et al., 2019] and circumvents the optimisation and context-window consumption issues associated with Prefix-Tuning [Li and Liang, 2021; Hu et al., 2022; Vgontzas et al., 2023]. Therefore, LoRA was the most suitable fine-tuning strategy, as its efficiency, zero-latency characteristic, and ability to preserve general knowledge were crucial for achieving the project's objectives.
3.3.4.1 - Choice for This Project
Its efficiency makes it feasible to conduct targeted experiments on smaller models to address specific linguistic weaknesses, such as Italian morphology. Its zero-latency characteristic and ability to preserve general knowledge are crucial for achieving the objective of improving linguistic performance without destroying the model's existing capabilities.
3.3.5 - Disadvantages of LoRA
LoRA is not without limitations. Its performance can lag behind full fine-tuning because the low-rank assumption is not always valid, which can cause an accuracy gap on complex domains like code and maths compared to full fine-tuning [Biderman et al., 2024]. Performance is also highly sensitive to hyperparameters, requiring careful tuning to approach the results of a full finetune [Biderman et al., 2024]. From a practical standpoint, LoRA presents memory challenges; serving thousands of small adapters can exhaust GPU memory, making it "infeasible" at scale [Brüel-Gabrielsson et al., 2025]. Furthermore, standard LoRA training can still demand substantial RAM for very large models, which necessitated the development of more memory-efficient variants like QLoRA [Dettmers et al., 2023].
3.4 - Quantisation
Quantisation is a model compression technique that addresses this issue. It reduces the numerical precision of a model's parameters, for instance, from 32-bit floating-point numbers to more efficient 4-bit integers. This process results in a much smaller memory footprint and can speed up computation. However, this process is inherently lossy and can introduce minor errors, potentially degrading a model's predictive performance.
For this project, quantisation is a crucial enabling technology. It makes it feasible to run experiments on larger models, such as the 24-billion-parameter Magistral-Small, on hardware with limited VRAM. While this introduces a risk of slight performance misalignment for the Magistral-Small model, it is an acceptable trade-off as it serves as a control, and this was a necessary compromise to ensure the experiment was computationally feasible. Specifically, this project utilises QLoRA, a method that combines quantisation with the parameter-efficient fine-tuning approach discussed in the next section. QLoRA allows for backpropagation through a frozen, 4-bit quantised model into a small set of trainable adapters, drastically reducing memory requirements during training with minimal impact on performance [Dettmers et al., 2023].
4 - Objectives
4.1 - Principal Objectives
The primary objective is to determine if the advanced reasoning capabilities found in newer LLMs can improve performance on complex Italian linguistic tasks. This research will test the hypothesis that these same reasoning skills, typically used for logical problems like mathematics, can also be applied to navigate the grammatical rules of the Italian language.
The second objective addresses a practical challenge. The reasoning process is slow and computationally expensive. Therefore, this project aims to improve the models' faster, non-reasoning mode through fine-tuning. The goal is to enhance linguistic performance so that the model is effective for everyday tasks without needing to "think".
However, this fine-tuning creates a critical risk. Specialised training can cause a model to lose its general abilities, including its core reasoning skills. The final and most important objective is therefore to solve this trade-off. The project aims to develop and validate a novel fine-tuning methodology that improves non-reasoning linguistic performance while also preserving and enhancing the model's advanced reasoning capabilities.
4.2 - Secondary Objectives
4.2.1 - Objective 1: Establish Validated Baseline
To support the primary objectives, the first task is to establish a validated baseline. This involves replicating the published results from the ITALIC benchmark for two key models. The first model is Llama 3.1 8B Ita, a variant of Llama 3.1 8B fine-tuned on Italian data and the best-performing small-scale model in the original study. The second is Mistral NeMo (12B parameters) which is a multilingual model that will serve as a control.
The goal is to consistently reproduce their benchmark scores, for both the final average accuracy and for each of the 12 individual categories, with a deviation of no more than 1.5%.
This validation is critical because the proven methodology can then be confidently applied to benchmark subsequent models, such as the reasoning-capable models, ensuring that any observed performance differences are due to the models themselves and not variations in the experimental setup.
4.2.2 - Objective 2: Evaluate Reasoning-Capable Models (Reasoning Disabled)
The next step is to evaluate modern hybrid reasoning models with their reasoning capabilities disabled. This will involve benchmarking the Qwen3 series of models, which are available in various sizes allowing for an analysis of scaling effects. To ensure the findings are not specific to one model family, Magistral-Small (available only as 24B parameters) model will also be evaluated.
This step is important because it establishes a baseline performance for the general architecture of these models. It makes it possible to understand how much of any performance gain is from the reasoning process itself, rather than from the model's underlying design. The results from this evaluation will be directly compared against the performance of the same models when their reasoning is enabled.
4.2.3 - Objective 3: Evaluate Reasoning-Capable Models (Reasoning Enabled)
Following the baseline evaluation, the same reasoning-capable models (Qwen3 series and Magistral-Small) will be benchmarked again, but this time with their reasoning capabilities enabled. The primary goal is to measure the performance difference between the reasoning-enabled and reasoning-disabled states. This will show how much the reasoning process contributes to the models' performance.
A key part of this analysis will be to check if the performance gap between cultural knowledge and language understanding closes. If reasoning does lead to significant improvements, a qualitative analysis will be performed. This involves comparing questions that were answered incorrectly when reasoning was disabled to those that are now correct to understand how the reasoning process helps solve complex linguistic problems. Completing this evaluation will fulfil the first primary objective of the research.
4.2.4 - Objective 4: Implement Supervised Fine-Tuning
The next step is to fine-tune the models. This will be done using the regular LoRA technique. The reasoning models (Qwen3 and Magistral-Small) will be fine-tuned on the Mult-It dataset, a broad Italian question-answer dataset that is well-aligned with the ITALIC benchmark format. This dataset covers many of the known linguistic weaknesses of the models. For comparison, a non-reasoning model, Llama 3.1 8B Ita, will also be fine-tuned as a control. The specific aim of this fine-tuning is to improve performance in the three weakest linguistic areas: morphology, orthography, and syntax.
4.2.5 - Objective 5: Evaluate Fine-Tuned Models
The final task is to benchmark the models after fine-tuning. The fine-tuned reasoning models will be evaluated twice using the same established pipelines: once with reasoning disabled and once with reasoning enabled. The fine-tuned Llama 3.1 8B Ita control model will also be benchmarked.
First, the evaluation will measure the performance improvement with reasoning disabled to see if the fine-tuning successfully closed the gap with cultural and commonsense knowledge. To prevent catastrophic forgetting, it is also crucial that the models do not perform worse in these existing areas of strength.
If the gap is closed, the analysis will then focus on the impact to the reasoning process itself. It will explore whether the fine-tuned models can combine the new linguistic knowledge with their reasoning, whether there is no effect, or if reasoning performance has worsened. A detailed analysis will be conducted to understand the reasons behind these outcomes.
5 - Specifications
5.1 - General Project Specifications
These requirements apply across all phases of the project.
- Model Architecture: All models selected must be publicly available, open-weight, decoder-only LLMs based on the Transformer architecture.
- Computational Constraints:
- Models selected for benchmarking must have fewer than 35 billion parameters.
- Models selected for fine-tuning must have fewer than 15 billion parameters due to higher memory overhead.
- Benchmark: All evaluations must use the ITALIC benchmark in a zero-shot setting [Seveso et al., 2025].
- Hardware & Software:
- All experiments must be executable on a single NVIDIA GPU with up to 40GB of VRAM. Most of the experiments can be carried out on a single NVIDIA RTX 3090 with 24GB of VRAM. At least CUDA 12.1 is needed.
- The software stack must use standard open-source libraries like PyTorch and Hugging Face transformers, peft, and trl.
- Answer Extraction: An automated, REGEX-based parser is required to extract and score answers from model outputs with high accuracy.
5.2 - Phase 1: Baseline Replication Specifications
This initial phase is designed to validate the experimental framework.
- Model Requirements: Two non-reasoning models from the original ITALIC study must be used.
- Llama 3.1 8B Ita (DeepMount00/Llama-3.1-8b-ITA): An 8-billion-parameter model specifically fine-tuned for Italian.
- Mistral NeMo (mistralai/Mistral-Nemo-Instruct-2407): A 12-billion-parameter general-purpose multilingual model.
- Process Requirements: Each model must be benchmarked three times to assess consistency.
- Performance Criteria: This phase will be considered successful if the evaluation pipeline is validated.
- The replicated average accuracy scores must be within a ±1.5% margin of the results published in the ITALIC paper.
- The results must show a low standard deviation across the three runs, ensuring the findings are reproducible and statistically sound.
5.3 - Phase 2: Reasoning Capability Analysis Specifications
This phase is analytical and aims to determine if reasoning capabilities affect performance on linguistic tasks.
- Model Requirements: The evaluation requires a set of hybrid reasoning models capable of operating with and without a reasoning process. This is crucial to isolate architectural improvements from the effects of reasoning.
- Qwen3 Series: Models of varying sizes (Qwen/Qwen3-0.6B, Qwen/Qwen3-1.7B, Qwen/Qwen3-4B, Qwen/Qwen3-8B, Qwen/Qwen3-14B, Qwen/Qwen3-32B) must be used to analyse scaling effects.
- Magistral-Small (mistralai/Magistral-Small-2506): A 24-billion-parameter reasoning model from a different family will serve as a control to ensure findings are not architecture-specific.
- Process Requirements: Each model must be benchmarked twice: once with reasoning disabled to set a baseline, and once with reasoning enabled.
- Performance Criteria: Success in this phase is defined by the quality of the analysis.
- The analysis must provide a clear, data-driven and statistically significant conclusion on whether reasoning improves, degrades, or has no effect on linguistic tasks.
- The analysis must also provide a qualitative explanation for why these changes occur, based on the models' outputs.
5.4 - Phase 3: Fine-Tuning Intervention Specifications
This phase is contingent on Phase 2 demonstrating that reasoning provides a performance benefit. The goal is to create a more efficient model by enhancing its non-reasoning capabilities while still making reasoning accessible for more complex tasks.
- Model Requirements: The fine-tuning process must use the hybrid reasoning models from Phase 2.
- Process Requirements: The intervention must use a parameter-efficient fine-tuning (PEFT) technique, specifically LoRA (due to its efficiency) to modify the models. The primary dataset for this process must be Mult-IT [Rinaldi et al., 2024].
- Performance Criteria: The fine-tuned model (the artefact) will be considered a success if it meets three simultaneous conditions:
- Improved Efficiency: The model's non-reasoning performance on linguistic tasks must show statistically significant improvement. This is critical for practical applications like customer service agents, where the latency and computational cost of the reasoning mode are prohibitive.
- Reasoning Preservation: The model's core reasoning capability must remain intact and functional. A loss of this ability constitutes a failure.
- Knowledge Preservation: The model must not exhibit catastrophic forgetting. Performance in cultural knowledge categories must not degrade significantly.
6 - Design
This chapter presents the architectural blueprint of the project. The entire experimental design is hypothesis-driven, structured in two main phases to systematically test the project's core claims. The first phase, Benchmarking, was designed to test the initial hypothesis that modern reasoning capabilities can improve performance on complex linguistic tasks. The second phase, Iterative Fine-Tuning, was designed as an experimental process to find the most effective way to enhance the model's efficient, non-reasoning performance while preserving its advanced reasoning capabilities.
6.1 - Benchmarking Design
The initial phase of the project was designed to systematically evaluate and compare the performance of various models on the ITALIC benchmark [Seveso et al., 2025]. This required a reliable experimental framework and a clear analytical strategy to test the first hypothesis. The process began by benchmarking the two models from the original ITALIC study to validate the pipeline. Following this validation, the reasoning-capable models were benchmarked with and without their reasoning modes enabled.
6.1.1 - Experimental Framework Architecture
The experimental framework was designed as a modular pipeline to ensure a standardised and repeatable process for benchmarking each LLM. This design allows for consistent data handling, prompting, inference, and evaluation. The same core pipeline was used for all non-reasoning evaluations to ensure consistency. The reasoning benchmark was a direct extension of this pipeline, also applied uniformly across all relevant models. This consistency was critical for making valid comparisons. A high-level overview of this pipeline is shown in Figure 6.1.
Figure 6.1: Experimental Pipeline Architecture
Figure 6.1: Experimental Pipeline Architecture
- ITALIC Dataset: The main benchmark for evaluating the models' alignment [Seveso et al., 2025].
- Prompt Templating Engine: Formats each question into a consistent zero-shot prompt. For standard evaluations, the prompt was identical to the one used in the original ITALIC paper to prevent the prompt from influencing the results. For reasoning evaluations, this prompt was extended with an aggressive instruction for the model to "think briefly". This was designed to elicit a thought process while preventing the excessively long and slow outputs that can occur with unconstrained reasoning.
- Model Inference Engine: All model inference was handled by the vLLM engine, chosen for its high-throughput batching and efficient memory management.
- Output Parsing & Answer Extraction: A REGEX-based parser was designed with multiple patterns to reliably handle the different output formats from models in both non-reasoning and reasoning modes. The parser was designed with multiple, ordered REGEX patterns to handle common variations (e.g.,
FINALE: B,Answer: B, or a standaloneB), ensuring robust and accurate extraction across different model outputs. An alternative approach, using a second language model to intelligently parse the output, was also considered. This was rejected because it would be significantly slower, less predictable, and would add unnecessary complexity to the pipeline compared to the deterministic REGEX method. - Scoring Module: Compares the extracted answer with the ground-truth answer.
- Results Aggregation & Analysis: Collates scores to calculate overall and category-specific accuracies.
6.1.2 - Model Selection Rationale
The selection of models was a core part of the experimental design, chosen to establish a valid baseline and to systematically test the project's hypotheses.
6.1.2.1 - Baseline Models
To ensure the validity of the experimental framework, two models from the original ITALIC study were selected to replicate the published results:
- Llama 3.1 8B Ita: Chosen as the primary baseline for a small-scale, language-adapted model.
- Mistral NeMo: Chosen as a control to validate accuracy of the framework.
6.1.2.2 - Reasoning-Capable Models
To investigate the project's central hypotheses, modern hybrid reasoning models were selected. This was a critical design choice, as these models allow reasoning to be toggled ON and OFF. This feature makes it possible to isolate the performance impact of the reasoning process itself from general architectural improvements. Purely reasoning-focused models like DeepSeek R1 were unsuitable because they do not offer this switchable functionality.
- Qwen3 Series (0.6B to 32B): This model family was chosen specifically to design an experiment for analysing scaling effects.
- Magistral-Small: This model was selected as a crucial control. As it belongs to a different architectural family, its inclusion was designed to ensure the project's findings were not architecture-specific. To maintain experimental consistency, this model was benchmarked with 4-bit quantization from the start, ensuring a fair comparison with its post-QLoRA fine-tuned version (which requires quantization).
6.1.3 - Comparative Analysis Design
The initial benchmarking was designed around two key comparisons:
- Baseline vs. Reasoning-Enabled Analysis: This analysis was designed to directly test the first project hypothesis. To isolate the impact of the reasoning process, the same models were tested in two distinct modes. This direct comparison allows for a quantitative measurement of the performance gain attributable solely to step-by-step thinking.
- Pre- vs. Post-Fine-Tuning Analysis: This comparison was conducted after each fine-tuning iteration to measure the effectiveness of the intervention. To facilitate this iterative cycle, the benchmarking framework was designed to load a locally stored LoRA adapter, merge it with the base model, and then run the full evaluation.
6.2 - Iterative Fine-Tuning Design
Following the initial benchmarking, a multi-stage fine-tuning process was designed to address the linguistic weaknesses identified in the reasoning models. This process was designed to test the second hypothesis: that a targeted intervention could enhance the efficient non-reasoning mode while preserving advanced reasoning capabilities. This was approached as an iterative experimental cycle. The initial experiment established a baseline, but its results revealed an unexpected and critical challenge, which required subsequent experiments to diagnose and solve.
To conduct these experiments, several models were selected for specific reasons. The Qwen3 4B, Qwen3 8B, and Magistral-Small models were chosen because they are all hybrid reasoning models. Qwen3 8B is the same scale as Llama 3.1 8B Ita, allowing for direct comparisons. To validate the intervention's effectiveness on a standard model, Llama 3.1 8B Ita was also fine-tuned as a non-reasoning control.
Figure 6.2: Fine-Tuning and Evaluation Cycle
6.2.1 - Core Fine-Tuning Technology Rationale
The foundational choices for the fine-tuning methodology were as follows:
6.2.1.1 - Parameter-Efficient Fine-Tuning (PEFT)
PEFT was chosen over Full Fine-Tuning (FFT) as it is less computationally expensive and, crucially, carries a lower risk of catastrophic forgetting as discussed in Section 3.3.
6.2.1.2 - Low-Rank Adaptation (LoRA)
As established in the Background Theories Section 3.4, LoRA was selected as the specific PEFT method because it offers the best balance of parameter efficiency, high performance, and zero additional inference latency. For the Qwen3 models, standard LoRA was used. However, for the largest model, Magistral-Small (24B), the design was adapted to use QLoRA. This was a necessary choice dictated by the memory constraints as defined in the project specification, making fine-tuning feasible on the available hardware.
6.2.1.3 - Dataset Selection
The Mult-IT dataset was chosen for its direct alignment with the ITALIC benchmark's format and content [Rinaldi et al., 2024]. Alternative datasets were rejected after initial tests showed they were ineffective:
- MorphyNet: This dataset's format of inflection tables was fundamentally different from the multiple-choice task [Batsuren et al., 2022]. Training on it did not improve morphology performance and caused performance in other areas to degrade.
- BLM-CausI & BLM-Odl: These synthetic datasets used a narrow, rule-based prediction task [de la Cruz et al., 2024]. This format did not align with the broader knowledge required by ITALIC and failed to produce improvements, while also degrading performance.
6.2.2 - Iterative Approach to Hybrid Model Training
The project's central challenge (improving linguistic performance without destroying reasoning ability) was solved through an iterative experimental process:
- Experiment 1 (Regular PEFT): The cycle began by fine-tuning the models on the standard Mult-IT dataset. The subsequent benchmark evaluation confirmed this improved non-reasoning performance but revealed a catastrophic failure of the reasoning function.
- Experiment 2 (CoT-only PEFT): To diagnose and solve this issue, a second experiment was designed. This involved fine-tuning the model exclusively on a dataset of synthetic CoT examples. The benchmark results proved that this method restored reasoning but failed to improve non-reasoning performance. The synthetic CoT dataset was then merged with the original dataset, replacing duplicate questions to create the final hybrid dataset.
These preliminary experiments established that neither data format alone was sufficient. This led to the design of the final, novel hybrid approach.
6.2.3 - Final Hybrid Design (Novel Technique)
Figure 6.4: Synthetic Only Test Pipeline
Figure 6.5: Hybrid Training Pipeline
6.2.3.1 - Synthetic Data Generation
The hybrid dataset was created by augmenting the Mult-IT training data. The reasoning-enabled benchmarking pipeline was repurposed to run on the Mult-IT training set, generating CoT for approximately 18,000 correctly answered questions. This process was run independently for each model to create model-specific training data, respecting their unique internal monologues (e.g., Qwen3 thinking in English vs. Magistral in Italian). These 18,000 questions were used in experiment 2 without the standard Q&A samples first before this novel hybrid approach was finalised.
6.2.3.2 - Implementation
The hybrid training was implemented using the SFTTrainer from the trl library. A custom formatting function was designed to dynamically construct training examples using the model's chat template, inserting the synthetic thinking content for the augmented samples.
6.2.3.3 - Fine-Tuning as Regularisation
The final design mixes the ~18,000 synthetic CoT samples with the standard question-answer samples at a ratio of approximately 1:5. This treats the data as a form of bidirectional regularisation. The CoT samples periodically "remind" the model how to reason, while the more numerous standard samples prevent it from overfitting on the synthetic CoT. The final benchmark confirmed this design was highly successful.
6.2.3.4 - Alternative Design: Sequential Fine-Tuning
An alternative, sequential fine-tuning approach was also considered. This method involved two distinct steps. First, the model would undergo LoRA fine-tuning on the Mult-IT dataset to improve linguistic performance, just as in the first experiment. Afterwards, a second round of fine-tuning would be performed exclusively on the synthetic CoT data to restore the lost reasoning, similar to the second iteration.
However, this design was rejected because it is fundamentally suboptimal. The first training phase causes the model to suffer catastrophic forgetting of its original reasoning ability. The second phase would therefore not be preserving an existing skill but attempting to re-teach it from scratch using a limited dataset. The model's original reasoning was developed by its creators using sophisticated techniques like RLVR. Any re-taught ability would likely be a pale imitation of this powerful, pre-existing function. The final hybrid design is superior because it mixes both data types, allowing the model to learn new linguistic patterns while simultaneously being "reminded" how to reason, thus preserving its core capabilities.
7 - Methodology & Implementation
This chapter details the strategic methods and concrete technical implementations used in the project. It is structured in two phases. The first phase describes the design and validation of the analytical framework, a novel analytical contribution used to test the project's primary hypotheses on model performance. The second phase will detail the fine-tuning intervention that produced the final model artefacts using a novel hybrid training method.
7.1 - Phase 1: Analytical Framework for Benchmarking
7.1.1 - Benchmarking for Standard Non-Reasoning
7.1.1.1 - Methodology
The core method involved a standardised, zero-shot evaluation on the ITALIC benchmark [Seveso et al., 2025]. This approach was applied consistently across all models to ensure fair and reliable comparisons. The initial pipeline was carefully implemented based on the descriptions in the original ITALIC paper.
7.1.1.2 - Implementation
For the Llama, Mistral, and Qwen model families, the pipeline was implemented using the vLLM library. This choice was crucial for efficiently processing the 10,000-sample dataset on a single GPU. The codebase was built with a modular, class-based architecture (e.g., QwenBenchmark, Llama31Benchmark). This design simplified the workflow, making it easy to benchmark different model sizes and configurations without code repetition. Configuration for each experiment was managed through dedicated classes like QwenBenchmarkConfig, which allowed for precise control over parameters such as model_name, batch_size, and max_new_tokens.
A key difference in implementation was required for Magistral-Small. At the time of this project, vLLM did not fully support 4-bit quantisation. Therefore, its benchmarking pipeline was implemented using the standard Hugging Face transformers library with BitsAndBytesConfig for 4-bit nf4 quantisation, which was much slower. This pipeline was further optimised by enabling torch.compile and Flash Attention 2 where available, as configured in the MagistralBenchmarkConfig. A deliberate choice was made to use the tokenizer from mistralai/Mistral-Nemo-Instruct-2407, as this was the recommended and compatible tokenizer for the Magistral model at the time.
The QwenBenchmark, Llama31Benchmark, and MagistralBenchmark classes include a _merge_lora_adapters method, which uses the peft library to load a trained LoRA adapter, merge its weights with the base model, and then load the resulting merged model into vLLM for high-speed inference. This integrated workflow was essential for efficiently evaluating the artefacts produced in the second phase of the project.
7.1.1.3 - Benchmarking Hyperparameters
Most hyperparameters, such as batch_size, depend on the available GPU memory and do not affect the model's accuracy. For all non-reasoning evaluations, greedy decoding was used to ensure deterministic and consistent outputs as outlined in the ITALIC paper.
- For the Llama 3.1 8B Ita and Mistral NeMo models, the parameters were set to
max_new_tokens=350for both models andmax_length=8192for NeMo. - For the Qwen3 series and Magistral-Small, the parameters were set to
max_length=8192andmax_new_tokens=150.
7.1.2 - Benchmarking for Reasoning
7.1.2.1 - Methodology
The reasoning-capable models were benchmarked twice: once with reasoning disabled to set a baseline, and once with reasoning enabled to measure the performance change. This comparative method forms the basis of the project's novel analytical contribution.
7.1.2.2 - Implementation
- Qwen3 Series (Native API): The Qwen3 models provide a native API for enabling reasoning at the inference level. As shown in the
QwenReasoningBenchmarkclass, the call toself.model.chat()was modified to include the argumentchat_template_kwargs={"enable_thinking": True}. This flag instructs the model to generate its internal monologue within<think>tags. - Magistral-Small (Manual Template Construction): Magistral-Small requires a more manual implementation. Its tokenizer does not have an automated flag for reasoning. Instead, the
format_promptfunction in theMagistralFineTuningclass was engineered to manually construct the chat template according to the model's documentation, correctly placing the<think>tags between the[INST]...[/INST]user tags and the final answer.
7.1.2.3 - Reasoning Hyperparameters
For the reasoning-enabled benchmarks, a non-deterministic sampling strategy was required, as greedy decoding can cause performance degradation and endless repetitions in the models' thought processes [Qwen Team, 2024b].
- For the Qwen3 series, the models were configured with a Temperature of 0.6, TopP of 0.95, and TopK of 20, as recommended by the model's documentation [Qwen Team, 2024b].
- For Magistral-Small, the configuration used a temperature of 0.7 and top_p of 0.95 [Mistral AI, 2025].
7.1.3 - Prompting & Answer Parsing
7.1.3.1 - Methodology
A data handling protocol was essential for the integrity of the results. This involved using specific prompt templates for each evaluation mode and implementing parsers capable of accurately extracting answers from varied model outputs.
7.1.3.2 - Implementation
Two primary prompt templates were implemented. For non-reasoning evaluations, the prompt was identical to the one used in the original ITALIC paper. For reasoning-enabled evaluations, this was extended with an instruction for the model to "think briefly" and conclude with a FINALE: X tag, as detailed in the Specifications (Section 5.2).
This necessitated two separate answer extraction functions:
extract_answer_robust: A multi-pattern REGEX parser for standard outputs.extract_answer_with_reasoning: A more sophisticated parser with a hierarchical logic. It was engineered to first locate the closing<think/>tag and exclusively parse the text that followed. Only if this failed would it fall back to searching for other keywords likeFINALE:. This tailored approach was crucial for reliably handling the specific output format of the reasoning models.
This dual-parser system was a crucial implementation detail for ensuring accurate, automated scoring across all experimental conditions.
7.1.4 - Framework Validation & Reliability
7.1.4.1 - Methodology
The entire analytical framework was validated by replicating the published results for Llama 3.1 8B Ita and Mistral NeMo from the original ITALIC paper.
7.1.4.2 - Outcome
The framework successfully met the strict validation criteria. The replicated scores were highly accurate (e.g., within 0.17 percentage points for Llama 3.1 8B Ita). This successful validation provides definitive proof of the framework's reliability and confirms that the implementation is correct, serving as "adequate and effective testing". This trusted pipeline was then used for all subsequent evaluations.
7.2 - Phase 2: Fine-Tuning Intervention & Artefact Creation
This phase addressed the second hypothesis: that a targeted intervention could improve non-reasoning performance while preserving the model's core reasoning ability. The initial fine-tuning experiments revealed an unexpected and critical challenge (catastrophic forgetting of the model's reasoning abilities) which required the development of a novel hybrid training technique.
7.2.1 - LoRA Fine-Tuning
7.2.1.1 - Methodology
LoRA was chosen for its parameter efficiency and to mitigate the risk of catastrophic forgetting as detailed in Section 3.3. As detailed in Section 3.4, QLoRA was selected for the larger Magistral-Small model as it enables fine-tuning on quantised models, making the process feasible on the available hardware. The primary training data was the Mult-IT dataset [Seveso et al., 2025]. This choice was the result of a systematic investigation; preliminary experiments with more specialised datasets like MorphyNet proved ineffective as specified in section 6.2.1.3.
7.2.1.2 - Implementation
For Magistral-Small, the MagistralFineTuning class implemented QLoRA by first configuring a BitsAndBytesConfig for 4-bit nf4 quantisation, and then calling prepare_model_for_kbit_training to correctly prepare the quantized model for training. Training was managed by the SFTTrainer, which was configured to use an 8-bit AdamW optimiser to further manage memory usage. For all models, training efficiency was maximised by enabling sequence packing=True in the SFTConfig, which combines multiple short examples into a single sequence to improve throughput.
7.2.1.3 - LoRA Hyperparameters
To ensure the fine-tuning process can be reproduced, a consistent set of hyperparameters was used for the LoRA configuration, based on established best practices.
- Rank (r) = 24: This value was chosen as a balance between model capacity and parameter efficiency, sitting within the typical range of 8-64 used in successful LoRA implementations [Balandat et al., 2024; Hugging Face, 2025].
- Alpha (α) = 48: This follows the common practice of setting alpha to twice the rank [Hugging Face, 2025; Raschka, 2023].
- Dropout = 0.1: A standard dropout rate was applied to the LoRA layers for regularisation, which helps prevent overfitting [Wang et al., 2024].
- Target Modules: LoRA was applied to all linear layers within the model's attention blocks (
q_proj,k_proj,v_proj,o_proj) and the feed-forward networks (gate_proj,up_proj,down_proj).
7.2.2 - Iterative Experimental Process & Novel Hybrid Technique
The initial fine-tuning attempt revealed a critical flaw, necessitating an iterative experimental process that culminated in a novel hybrid training technique.
7.2.2.1 - Regular SFT
The first iteration used standard Supervised Fine-Tuning (SFT) on the Mult-IT dataset. While this successfully improved non-reasoning performance, it led to a catastrophic degradation of the reasoning function, as analysed in Section 9.4.1.2.
7.2.2.2 - CoT-Only Training
To diagnose and solve this issue, a second experiment was designed. This involved fine-tuning the model exclusively on a dataset of synthetic CoT examples. The benchmarking pipeline was adjusted to do so by simply passing the training dataset instead of the benchmarking dataset. A diagnostic training run on this synthetic data confirmed it successfully restored the model's reasoning ability (Section 9.4.2).
7.2.2.3 - Hybrid Training Method
These preliminary experiments established that neither data format alone was sufficient. This led to the design of the final, novel hybrid training method which is a novel technical contribution.
7.2.2.3.1 - Methodology
The hybrid dataset was created by augmenting the Mult-IT training data with synthetic CoT examples at a ratio of approximately 1:5, treating the CoT data as a form of regularisation, as discussed in the Design chapter.
7.2.2.3.2 - Implementation
The hybrid training was implemented using a sophisticated, adaptive training system. A ThinkingMode enum was used to control the training type. The configuration classes (e.g., QwenFineTuningConfig) were implemented to automatically adjust hyperparameters based on this mode; for example, when a thinking mode was enabled, max_length was increased and batch_size was reduced to accommodate the longer context windows. The format_prompt function then used this configuration to dynamically check each data sample for a 'thinking' key and apply the correct chat template for the respective model. This sophisticated, adaptive implementation was the key to successfully training a model that excelled in both non-reasoning and reasoning modes, as demonstrated in the final results (Section 9.4.3).
8 - Results, Analysis & Evaluation
This chapter measures the performance of the selected models against the stated objectives. The primary focus will be on the Qwen3 8B model, with other models serving as controls to validate the results. Statistical significance is shown using McNemar's Test with a significance threshold of p < 0.01. The code used for this computation is available in Appendix E.
8.1 - Baseline Validation
The project began by replicating the published ITALIC benchmark results for key models (Llama 3.1 8B Ita and Mistral NeMo). This section presents the findings for Llama 3.1 8B Ita, the best-performing small-scale model from the original study [Seveso et al., 2025].
8.1.1 - Llama 3.1 8B Ita
The replicated scores are presented in Table 9.1. The results demonstrate a very close alignment with the reference scores published in the ITALIC paper [Seveso et al., 2025].
| Category | Replicated Result (%) | Reference Result (%) | Difference (%) |
|---|---|---|---|
| Art | 70.78 | 70.10 | +0.68 |
| Civic Education | 71.50 | 71.22 | +0.28 |
| Current Events | 82.70 | 82.61 | +0.09 |
| Geography | 79.06 | 79.26 | -0.20 |
| History | 77.66 | 77.40 | +0.26 |
| Literature | 67.17 | 67.17 | 0.00 |
| Tourism | 71.33 | 71.73 | -0.40 |
| Lexicon | 81.31 | 81.51 | -0.20 |
| Morphology | 51.71 | 52.14 | -0.43 |
| Orthography | 52.29 | 53.04 | -0.75 |
| Synonyms | 81.27 | 81.15 | +0.12 |
| Syntax | 53.52 | 53.65 | -0.13 |
| Total | 70.32 | 70.49 | -0.17 |
The results were highly consistent across all three runs. The standard deviation is 1.61 (consistent) which is expected as greedy decoding has been used for deterministic results.
The successful replication of the baseline results validates the pipeline. This ensures that subsequent evaluations of other models are reliable and that any observed performance differences are attributable to the models themselves, not variations in the testing procedure.
8.1.2 - Mistral NeMo
To further validate the pipeline, the multilingual model Mistral NeMo was also evaluated. This model serves as a control. The results are shown in Table 9.2.
| Category | Replicated Result (%) | Reference Result (%) | Difference (%) |
|---|---|---|---|
| Art | 66.02 | 66.33 | -0.31 |
| Civic Education | 69.71 | 69.27 | +0.44 |
| Current Events | 82.52 | 82.61 | -0.09 |
| Geography | 76.43 | 76.00 | +0.43 |
| History | 74.95 | 74.34 | +0.61 |
| Literature | 69.31 | 68.39 | +0.92 |
| Tourism | 67.45 | 67.76 | -0.31 |
| Lexicon | 79.90 | 79.37 | +0.53 |
| Morphology | 52.86 | 52.86 | 0.00 |
| Orthography | 56.23 | 55.61 | +0.62 |
| Synonyms | 74.03 | 74.25 | +0.22 |
| Syntax | 54.57 | 54.78 | -0.21 |
| Total | 68.68 | 68.53 | +0.15 |
The replicated results for Mistral NeMo also align closely with the ITALIC paper. The total accuracy of 68.68% is just 0.15 percentage points below the reference score. All individual categories are again well within the ±1.5% margin of error.
Similar to the previous validation, the results were stable across three runs. The standard deviation remained low at 1.84. This confirms that the experimental framework is robust and can reliably benchmark different models.
8.2 - Reasoning Models (Reasoning Disabled)
Following the baseline validation, modern reasoning-capable models were evaluated. Their reasoning capabilities were disabled for this initial test. This step establishes a performance baseline for their underlying architecture(s). The results are shown in Table 9.3, alongside key reference models for comparison.
Table 9.3: Performance of Reasoning Models with Reasoning Disabled
The results show a clear scaling effect within the Qwen3 model family. Performance improves consistently as the model size increases, which is expected. Two models are particularly noteworthy. The Qwen3 8B model achieved an accuracy of 70.17%. This is very close to the 70.49% score of Llama 3.1 8B Ita. This is a strong result, as Llama 3.1 8B Ita is specifically fine-tuned for Italian, while Qwen3 8B is a general multilingual model. However, Qwen3 8B still does not perform as well as the smaller-scale proprietary models like GPT-4o Mini (82.22%), Claude 3.5 Haiku (81.24%), and Gemini 1.5 Flash (81.66%), showing that more improvement is still required.
The largest open-weight model tested, Qwen3 32B, also shows strong performance. Its score of 80.19% is very competitive with the smaller proprietary models. It performs just 1.5% below the average of its main competitors. This demonstrates that larger open-weight models are closing the performance gap.
Additionally, the Qwen3 14B model scored 77.78%. This is significantly higher than the 68.53% achieved by the similarly sized Mistral NeMo (12B). This suggests a more capable underlying architecture in the Qwen3 series. These results provide a solid baseline before analysing the impact of enabling the models' reasoning capabilities.
An interesting observation is that the newer architectures in Qwen3 and Magistral seem more sophisticated. The average absolute difference between "Culture & Common Sense" and "Language Capability" for these models is 0.88. In contrast, the average for other open models tested in the ITALIC paper was 3.55, while proprietary models averaged 0.58. This shows these newer models might have more advanced architectures, bringing them closer to their proprietary counterparts.
When comparing 8B parameter models, the performance gap between the two main categories varies significantly. For Qwen3 8B, the difference is just 0.3. For the Italian-specialised Llama 3.1 8B Ita, it is 2.47, and for the standard Llama 3.1 8B, it is 3.92. The proprietary GPT-4o Mini has a very small gap of 0.05. While Qwen3 8B is still behind GPT-4o Mini, it performs competitively against Gemini 1.5 Flash (0.25 difference) and better than Claude 3 Haiku (0.88 difference). Again, this highlights that there are areas of improvement for these open-models as proprietary models of similar scale still perform better.
Furthermore, older models trained only on Italian data show a much higher average difference of 5.11. This suggests that newer open models are effectively closing the gap with proprietary models in terms of balanced multilingual cultural alignment.
8.3 - Reasoning Models (Reasoning Enabled)
To test the project's primary hypothesis, the same reasoning-capable models were evaluated again with their reasoning capabilities enabled. This analysis measures the direct impact of the reasoning process on performance over the previously established baseline with reasoning disabled. The improvements achieved by reasoning remain consistent with expectations.
Table 9.4: Performance Change with Reasoning Enabled (%)
Activating reasoning led to a clear performance increase across most models and categories. As shown in Table 9.4 and Figure 9.1, the improvements are often significant. While there are minor decreases (almost insignificant) in a few isolated cases, the overall trend is positive across all models.
Figure 9.1: Performance Difference Between Reasoning and No-Reasoning States
On average, enabling reasoning improved the total score by 3.27 percentage points. The benefit was more pronounced for linguistic tasks. The "Language Capability" score increased by an average of 3.93 points, compared to a 2.82 point increase for "Culture and Commonsense". The Qwen3 8B model again provides a compelling case. With reasoning enabled, its total score rose to 74.49%. This represents a 4.32 point increase over its own baseline and makes it significantly better than the Italian-specialised Llama 3.1 8B Ita (70.49%). The largest single improvement was also seen in the Qwen3 8B model, which gained 14.63 points in Orthography. The second-largest gain was 10.8 points in Synonyms for the Qwen3 1.7B model. Overall, the performance gains from reasoning far outweigh the rare and minor degradations. However, even with reasoning enabled, Qwen3 8B still does not match the performance of the similarly-sized proprietary models discussed earlier.
The largest open-weight model tested, Qwen3 32B, becomes particularly impressive with reasoning enabled. Its total score jumps to 83.52%. This not only surpasses its non-reasoning baseline but also outperforms all the smaller proprietary models, including GPT-4o Mini (82.22%) and Gemini 1.5 Flash (81.66%). Notably, the reasoning process boosts its linguistic score so much that its "Language Capability" (84.64%) is now higher than its "Culture and Commonsense" (82.76%). This inverts the typical performance trend and shows reasoning is highly effective for linguistic tasks.
A similar observation can be made about the performance gap between cultural and linguistic tasks. With reasoning enabled, the average absolute difference between the two categories increased slightly to 1.10, up from 0.88. For the Qwen3 8B model, this gap averaged 1.35, which is higher than its non-reasoning score of 0.3 but still much lower than Llama 3.1 8B Ita's 2.47. The scores also fluctuated more between runs, likely because greedy decoding was disabled, causing different thinking patterns across runs. However, the lowest gap observed for Qwen3 8B during a run was 0.39, close to its original stable score. This suggests that while reasoning boosts overall performance, it can introduce some instability and slightly unbalance the gains between different skill categories.
These results provide strong initial support for the hypothesis that reasoning capabilities can improve performance. The larger gains in language tasks suggest that breaking down a problem into steps is particularly helpful for navigating complex linguistic rules. The performance improvements are not as large as what has been seen when testing for mathematics and programming but still very significant [Wei et al., 2022]. These improvements are also statistically significant. A McNemar's test on the results confirms this with a p-value of approximately 0.00024, proving the performance gain is not due to random chance.
It is important to note that performance did not improve in every single case. The most significant degradation was observed in the Syntax category for Qwen3 14B, which scored 0.87 points lower with reasoning enabled. The standard deviation for the reasoning-enabled runs was also higher, at 6.48. This is an expected outcome, as greedy decoding could not be used. The model's documentation warns that this can cause loops in the thinking process, necessitating a non-deterministic approach.
Figure 9.2: Average Difference Across Models for Reasoning & Non-Reasoning
8.3.1 - Analysis of Scaling Effects
A key aspect of this investigation is understanding how the benefits of reasoning change as models increase in size. The data from the Qwen3 series provides a clear view of these scaling effects. As illustrated in Figure 9.3, both reasoning and non-reasoning modes show improved performance with increased model size. However, the performance uplift gained by enabling reasoning is most significant in the smaller models and gradually diminishes as the models become larger.
Figure 9.3: Accuracies for Reasoning & Non-Reasoning Based on Scale
The data reveals a clear trend of diminishing returns, which is also visible in the performance graph as the two curves begin to converge at larger scales. The largest performance gains from reasoning are concentrated in the smaller to mid-sized models. For instance, the Qwen3 1.7B model gains a substantial +5.66 percentage points, and the 8B model gains +4.32 points when reasoning is enabled. This benefit shrinks noticeably for the larger models, with the Qwen3 14B model gaining only +1.00 point. This pattern suggests that as models become more powerful, their baseline non-reasoning capabilities improve to a point where the explicit step-by-step thinking offers a smaller marginal benefit. This indicates that reasoning provides a structured problem-solving framework that is particularly effective for smaller models, allowing them to better leverage their existing knowledge. In contrast, larger models appear to have more sophisticated capabilities integrated into their baseline architecture, making their direct answers more reliable without the need for an explicit thought process.
It is worth noting that the Magistral-Small (24B) model presents a slight anomaly, showing a very large uplift of +6.84 points. This is higher than many of the smaller Qwen3 models and could indicate architectural differences between the model families, where Magistral's design may benefit more from the reasoning process even at a larger scale.
A weakness of this analysis is the focus on small to medium-sized models. Without evaluating very large-scale models, it is difficult to determine if this trend of diminishing returns continues or plateaus. Furthermore, the findings are based on a limited number of model architectures, and averaging the results across a wider variety of architectures would provide a more generalised conclusion on scaling effects.
8.3.2 - Analysis of Reasoning Process
To understand why reasoning improves performance, a qualitative analysis of the models' thought processes was conducted. This analysis supports the theory from Section 3.2 that the performance gain is due to the model breaking down the problem using more output tokens instead of an artefact of more training data. The thinking process was consistent across different model sizes and families, including Magistral-Small. The reasoning process also allowed the model to combine different concepts, such as grammar rules and word types, which it may not be capable of doing when forced to produce an immediate answer. The full outputs for these examples are detailed in Appendix A: Reasoning Process Examples.
A clear pattern emerged in cases where reasoning corrected an initial wrong answer. When reasoning was disabled, the model made a direct, and often incorrect, prediction. For example, when asked to identify which word from a list does not require a capital letter, the non-reasoning model incorrectly chose "Colorado".
With reasoning enabled, the model adopted a systematic and "transparent" approach as shown in Appendix 12.1.1. It first identified the core task and recalled the relevant grammatical rule: proper nouns require capitalisation, while common nouns do not. It then analysed each option individually, correctly classifying "Picasso" and "Colorado" as proper nouns and "Deputato" (deputy) as a common noun. This step-by-step process allowed the model to apply its knowledge correctly and select the right answer. The non-reasoning model's failure suggests it made a flawed statistical association without performing this logical analysis. This deliberate, structured thinking is the key reason for the improved accuracy, especially in rule-based linguistic tasks.
However, the reasoning process is not infallible. There are instances where the model articulates a logical thought process but still arrives at an incorrect conclusion as shown in Appendix 12.1.2. This often occurs when the model's underlying knowledge base is flawed or incomplete for a specific, nuanced question. For example, when asked to identify the correct function of a verb in a sentence, the model correctly identified the grammatical concept (the function of "essere" as a copula) but then proceeded to misinterpret the role of the verb in each of the provided options. It correctly identified the task but its analysis of each sentence was flawed, leading it to the wrong answer. This demonstrates a crucial distinction: the ability to reason is separate from the accuracy of the knowledge the model is reasoning about. The model can follow a logical structure but still fail if its initial premises or linguistic knowledge are incorrect.
8.4 - Fine-Tuning Interventions
Following the successful validation of the initial hypothesis (that reasoning capabilities can significantly improve linguistic performance), the project moved to its second primary objective. This phase investigates whether targeted fine-tuning can embed these linguistic improvements directly into the model, making them accessible in the faster, more efficient non-reasoning state. The goal is to achieve better performance with lower computational cost and latency while still keeping and possibly improving the reasoning capabilities.
8.4.1 - Fine-Tuning Intervention (Iteration 1)
The first iteration of this fine-tuning process yielded mixed results. On one hand, the intervention was highly successful for the models in their non-reasoning configuration. As hypothesised from the gaps in Section 2.5.3, performance in the weaker linguistic domains saw substantial gains across all tested models, effectively closing the gap with cultural knowledge and, in some cases, even surpassing it. Crucially, these improvements were achieved without any significant degradation in other categories, demonstrating a successful transfer of knowledge without catastrophic forgetting.
However, this success came at a cost. A preliminary analysis revealed that this specialised linguistic training had a severe and detrimental impact on the models' core reasoning capabilities.
8.4.1.1 - Evaluation of Fine-Tuned Models (Reasoning Disabled)
To quantify the impact of the fine-tuning, the models were evaluated using the already established benchmarking pipeline with their reasoning capabilities disabled. The results, presented in Table 9.5, show a consistent pattern of improvement across the board, validating the effectiveness of the LoRA-based approach for enhancing linguistic skills.
Table 9.5: Performance of Fine-Tuned Models with Reasoning Disabled (Iteration 1)
The analysis begins with the Llama 3.1 8B Ita control model. The fine-tuning resulted in a significant total accuracy improvement of 3.42 percentage points (from 70.49% to 73.91%). As hypothesised, the gains were unevenly distributed. The "Culture & Commonsense" category saw a modest improvement of 2.49 points, confirming that catastrophic forgetting was avoided and there wasn't as much room for improvement. In contrast, the target "Language Understanding" category saw a much larger increase of 4.8 points (from 66.83% to 71.63%). This result strongly supports the premise that linguistic tasks had more room for improvement. Consequently, the absolute performance gap between the two domains narrowed considerably from 2.47 to 1.54. This successful outcome on the control model validates the overall fine-tuning methodology.
A similar and even more pronounced trend was observed for the primary experimental model, Qwen3 8B. The "Culture & Commonsense" score improved by a modest 2.44 points, again demonstrating knowledge preservation and lack of room for improvements. The "Language Understanding" score, however, improved by a substantial 5.32 points. This improvement was so effective that it inverted the performance balance; the language score (75.05%) is now higher than the culture score (72.91%). This shifted the absolute performance gap from 0.30 to 0.86. The Qwen3 4B model exhibited nearly identical behaviour, reinforcing the conclusion that this effect is characteristic of the fine-tuning approach on this model family.
Magistral-Small was evaluated as a reasoning control. Despite being trained with the slightly different QLoRA technique, the results were remarkably consistent. It showed a 2.34 point improvement in culture and a 5.02 point improvement in language understanding (due to its much larger size). This reduced its already small performance gap from 0.70 to just 0.39, further confirming that the fine-tuning strategy is robust and generalisable across different reasoning-capable architectures.
In summary, the first iteration achieved its primary goal for the non-reasoning state. The intervention systematically and significantly improved performance on the targeted linguistic weaknesses across all models, narrowing or even inverting the original performance gap without causing degradation in areas of existing strength. This improvement was confirmed to be statistically significant, with a McNemar's test yielding a p-value of approximately 1.94e-14. This establishes a new, stronger baseline for the models in their efficient, non-reasoning mode.
8.4.1.2 - Evaluation of Fine-Tuned Models (Reasoning Enabled)
When the same fine-tuned models were evaluated with their reasoning capabilities enabled, the results were severely negative. The evaluation revealed a catastrophic degradation in the models' ability to "think". All fine-tuned reasoning models (Qwen3 4B, Qwen3 8B, and Magistral-Small) effectively forgot how to perform step-by-step reasoning.
Table 9.6: Performance of Fine-Tuned Models with Reasoning Enabled (Iteration 1)
This collapse is reflected in the stark performance drops. For Qwen3 8B, the total accuracy plummeted by 15.16 percentage points, from a baseline of 74.49% down to 59.33%. This collapse was confirmed to be statistically significant by a McNemar's test, which yielded a p-value of approximately 9.09e-24. This degradation was uniform across both major categories: "Culture and Commonsense" fell by 15.88 points (from 73.13% to 57.25%), and "Language Understanding" dropped by 14.07 points (from 76.49% to 62.42%). Similar catastrophic degradations were observed for Qwen3 4B (a 14.28 point drop) and Magistral-Small (a 14.3 point drop), confirming this is a systemic issue.
8.4.1.2.1 - Analysis of Reasoning Degradation
When prompted to reason, the fine-tuned models produced empty <think> tags. They generated no intermediate thought process or step-by-step analysis as shown in Appendix 12.2. Instead, they defaulted to providing a direct, final answer, mirroring the behaviour of their non-reasoning state. This occurred regardless of whether the final answer was correct or incorrect.
This behaviour strongly suggests that the fine-tuning process overwrote the model's learned ability to reason. The dataset used for fine-tuning, while effective for teaching linguistic patterns, consisted solely of question-answer pairs. It did not contain examples of Chain-of-Thought (CoT) reasoning. Conventional wisdom in training reasoning models indicates that they require exposure to datasets that explicitly model this thought process. The alternative, Reinforcement Learning from Verifiable Rewards (RLVR), is far more computationally expensive and time-consuming than the standard PEFT techniques used in this project. By training on a dataset without CoT examples, the model was effectively taught to ignore the reasoning step, leading to this catastrophic failure.
8.4.2 - Fine-Tuning Intervention (Iteration 2)
To address the catastrophic forgetting of reasoning abilities, a third fine-tuning iteration was conducted using a novel technique. This approach uses a hybrid mechanism where the model to be fine-tuned first generates its own "thinking" tokens for a subset of the training data. These synthetic CoT examples are then injected back into the training dataset.
For this initial test, a conventional approach was taken as a preliminary step. A subset of 18,000 samples was created, consisting exclusively of questions where the model had generated correct answers and their corresponding synthetic CoT reasoning. The original non-thinking samples were removed for this experiment. This allowed for a focused evaluation of whether training on CoT data could restore and improve reasoning performance. The accuracy of this data is not important for the purposes of this diagnostic test.
8.4.2.1 - Evaluation of Fine-Tuned Models (Reasoning Disabled)
This training approach had almost no effect on the models' non-reasoning performance. Qwen3 8B saw a negligible overall improvement of just 0.2 points. Its "Culture & Commonsense" score dipped slightly (-0.21 points) while its "Language Understanding" score saw a minor increase (+0.55 points). The other models, Qwen3 4B (+0.1 points) and Magistral-Small (+0.17 points), also remained static. However, a McNemar's test on the full dataset comparison showed that the overall improvement of 2.05% was statistically significant, with a p-value of approximately 4.2e-06.
Table 9.7: Performance of Fine-Tuned Models with Reasoning Disabled (Iteration 2)
This outcome demonstrates a clear trade-off. While training exclusively on CoT data successfully restores and boosts reasoning, it fails to deliver the linguistic improvements in the non-reasoning state that were achieved in the first iteration. This leaves a gap in the analysis, as it is unclear whether fine-tuning on a much larger dataset composed exclusively of CoT examples would cause a similar degradation in non-reasoning performance to what was observed in the reverse scenario.
8.4.2.2 - Evaluation of Fine-Tuned Models (Reasoning Enabled)
When reasoning was enabled, all models not only retained their lost abilities but surpassed their original baseline performance.
Table 9.8: Performance of Fine-Tuned Models with Reasoning Enabled (Iteration 2)
Qwen3 8B saw its total accuracy jump by 3.38 percentage points over its original reasoning baseline, reaching 77.87%. A McNemar's test confirmed this improvement was statistically significant, with a p-value of approximately 6.89e-12. This improvement was balanced, with "Culture & Commonsense" increasing by 3.44 points and "Language Understanding" by 3.3 points. Similar strong gains were observed for Qwen3 4B (+3.83 points overall) and Magistral-Small (+2.99 points overall). This confirms that training on synthetic CoT data is a highly effective method for enhancing a model's reasoning capabilities. This sets the stage for a true hybrid approach, which will combine both standard and CoT samples in the training data to pursue simultaneous improvements in both reasoning and non-reasoning modes.
8.4.2.2.1 - Analysis of Restored Reasoning
A qualitative analysis of the model outputs confirms that fine-tuning on CoT data successfully restored the models' reasoning abilities. As shown in the examples in Appendix C, all the fine-tuned reasoning models (Qwen3 4B, Qwen3 8B, and Magistral-Small) are once again able to generate a step-by-step internal monologue within the <think> tags before providing a final answer. The functionality is still the same as what was discussed in Section 8.3.1, so no further low-level analysis is needed.
This restored capability is evident regardless of whether the final answer is correct or incorrect. The models consistently articulate a logical process, identifying the core task, recalling relevant rules, and evaluating the options. This behaviour is the expected outcome, as training with CoT examples is the industry-standard method for teaching models to reason. The success of this conventional approach validates the synthetic CoT generation and provides a strong foundation for the next step: testing the full hybrid training method to improve the non-reasoning performance as well as to maintain and enhance both the reasoning capabilities.
8.4.3 - Fine-Tuning Intervention (Iteration 3 – Hybrid Approach)
The final iteration of fine-tuning tested the second hypothesis of this phase: that a hybrid training dataset, combining both standard question-answer pairs and synthetic Chain-of-Thought (CoT) examples, could simultaneously improve both non-reasoning and reasoning performance. This approach is specifically designed for hybrid reasoning models like Qwen3 and Magistral-Small, which can switch between operational modes.
8.4.3.1 - Evaluation of Fine-Tuned Models (Reasoning Disabled)
The results for the non-reasoning state were highly successful and closely mirrored the outcomes of the first iteration.
Table 9.9: Performance of Fine-Tuned Models with Reasoning Disabled (Iteration 3)
For Qwen3 8B, the overall performance increased by a significant 3.64 percentage points over its baseline (from 70.17% to 73.81%). A McNemar's test confirmed this improvement was statistically significant, with a p-value of approximately 8.32e-18. The gains were again weighted towards the target linguistic areas; "Culture & Commonsense" improved by 2.82 points (from 70.47% to 73.29%), while "Language Understanding" saw a larger increase of 4.11 points (from 69.73% to 74.58%). This resulted in a very respectable absolute performance gap of just 0.52.
Qwen3 4B achieved an overall improvement of 3.84 points, with culture improving by 2.93 points and language by 5.17 points. Magistral-Small improved by 3.32 points overall, with a 2.63 point gain in culture and a 4.35 point gain in language. Crucially, when compared to the first iteration (which used only standard data), the performance differences were negligible. For instance, Qwen3 8B's total score was only 0.04 points higher, with minor fluctuations such as a 0.32 point increase for culture and a 0.47 point dip for language. Similar minimal differences of approximately 0.1 points were seen for Qwen3 4B and Magistral-Small. This confirms that introducing a subset of CoT data into the training mix does not dilute the linguistic improvements for the non-reasoning state, but it also means that the two types are largely independent.
In terms of absolute performance, the analysis comparing these models to their proprietary counterparts of a similar size still applies. As detailed in section 9.4.1.1, while the fine-tuned open-weight models show significant improvement and better balance between cultural and linguistic tasks, they still do not match the overall performance of models like GPT-4o Mini or Gemini 1.5 Flash. However, the intervention has successfully brought their capabilities closer, validating the effectiveness of the fine-tuning strategy. The next crucial step is to determine if this hybrid method successfully preserved the models' ability to think.
8.4.3.2 - Evaluation of Fine-Tuned Models (Reasoning Enabled)
The hybrid training approach proved to be a resounding success for the reasoning-enabled state. Not only was the catastrophic forgetting of the thinking capability from the first iteration completely avoided, but the models also demonstrated improved reasoning performance over their original baseline.
Table 9.10: Performance of Fine-Tuned Models with Reasoning Enabled (Iteration 3)
For Qwen3 8B, the overall accuracy increased by 3.08 points over its original reasoning baseline (from 74.49% to 77.57%). A McNemar's test confirmed this improvement was statistically significant, with a p-value of approximately 4.66e-13. The gains were well-distributed, with "Culture & Commonsense" improving by 3.3 points (from 73.13% to 76.43%) and "Language Understanding" by 2.76 points (from 76.49% to 79.25%). This result is closely aligned with the performance seen in the second iteration (which used only CoT data), with an overall difference of just 0.3 points; again this proves that the two types are largely independent. Importantly, no categories saw significant degradation, meaning there is not catastrophic forgetting. The absolute performance gap between the two domains was 1.14, a slight reduction from the baseline of 1.35, indicating a more balanced model.
The other models showed similarly positive outcomes. Qwen3 4B achieved an overall improvement of 2.81 points, with increases in both culture and language areas and no significant dips in any category. Likewise, Magistral-Small saw a 2.59 point increase, showing similar positive outcomes to Qwen3 8B across the board. These results strongly suggest that injecting a relatively small amount of CoT data into a larger dataset is sufficient for a model to retain and even enhance its ability to reason.
8.4.3.2.1 - Analysis of Hybrid Reasoning
A qualitative analysis of the outputs confirms that the hybrid training was successful. As shown in the examples in Appendix D, the models are once again able to produce a step-by-step internal monologue similar to what was analysed in Section 8.3.1. For a question about syllabic division, the model correctly breaks down the word, considers the options, and applies its knowledge to find the correct answer, a task its non-reasoning counterpart failed. This behaviour, which was lost after the first fine-tuning iteration, has been fully restored and was observed across all tested models, including Qwen3 4B and Magistral-Small.
Even when the model arrives at an incorrect answer, the underlying reasoning process is still sound. For instance, when asked for the plural of "film," the model correctly identifies the linguistic ambiguity between "filmi" and "filmati" and attempts to reason through the nuances, even though its final choice is wrong. This demonstrates that the ability to reason has been fundamentally restored, separating the logical process from the factual accuracy of the knowledge base.
8.5 - Weaknesses of Evaluation
This evaluation has several limitations. These weaknesses are primarily due to resource constraints and the novelty of the models studied. They offer clear directions for future work.
First, the study revealed a trade-off between standard fine-tuning and reasoning ability. Fine-tuning on a large question-answer dataset caused the models to forget how to reason. A key unanswered question is whether the reverse is true. We did not test if fine-tuning on a large, synthetically generated CoT dataset would degrade performance on standard, non-reasoning tasks. This remains an important area for future investigation. Such an experiment would clarify the relationship between these two modes.
Second, the analysis was restricted to a narrow range of model architectures. The project focused mainly on the Qwen3 family and one Magistral model. This was a necessary limitation. At the time of this project, very few open-weight hybrid reasoning models were available. A broader study including more architectural diversity would provide more generalisable insights.
Third, the evaluation did not include very large-scale models. This was due to the same lack of model availability and the significant computational resources required. The project could not explore whether the observed performance patterns hold true for models with hundreds of billions of parameters. Access to greater computing power would be needed to conduct such an analysis.
Finally, fine-tuning was only performed on smaller models. It is unclear if the successful hybrid-tuning approach would be equally effective at a larger scale. The computational cost of fine-tuning models with more than 30 billion parameters was prohibitive. Future work should test if these fine-tuning effects are consistent across different model scales.
8.6 - Conclusion of Findings
The results from this comprehensive evaluation confirm the success of all the project's hypotheses. The investigation has demonstrated a clear and effective pathway to improving the linguistic performance of smaller, open-weight language models for the Italian language.
First, the initial hypothesis was proven correct. Enabling the models' built-in reasoning capabilities consistently improved performance, particularly in the target linguistic tasks. As shown in the graph below, every model saw an increase in its "Language Understanding" score when thinking was enabled. For example, the Qwen3 8B model's language accuracy jumped from 69.73% to 76.49%, showing that a step-by-step process helps navigate complex grammatical rules.
Second, the project successfully analysed and overcame the challenges of fine-tuning. The initial fine-tuning attempt revealed a critical side effect: while it improved non-reasoning performance, it caused a catastrophic forgetting of the model's ability to think. To solve this, a novel hybrid training technique was developed. This method, which combined standard question-answer pairs with synthetically generated CoT examples, was highly effective. The final fine-tuned Qwen3 8B model not only improved its non-reasoning score to 73.81% but also enhanced its reasoning performance to 77.57%. It has also been found that the two modes are largely independent when training, as training of one mode does not improve the other (but can cause degradation).
Figure 9.4: Summary of Model Accuracy Against Reference Models, Base Models and Fine-Tuned Models
Crucially, these improvements did not come at the cost of the models' existing strengths. The fine-tuning process avoided catastrophic forgetting, as performance in "Culture & Commonsense" categories was maintained or slightly improved. The final models are now better aligned linguistically, making them more practical for everyday usage like customer service bots, where the speed of the non-reasoning mode is essential. For more difficult situations that require deeper analysis, the improved reasoning capability remains fully functional, providing a versatile and powerful tool.
9 - Legal, Social, Ethical & Professional Issues
Developing and deploying LLMs involves significant responsibilities that extend beyond technical implementation. This chapter provides a thoughtful discussion of the legal, social, ethical, and professional issues relevant to this project. It outlines the professional standards that guided the work, the ethical implications of enhancing Italian LLMs, and the project's approach to software trustworthiness, sustainability, and its potential economic impact. This discussion demonstrates a commitment to responsible research and development in AI.
9.1 - Professional Standards, Data Privacy, & Licensing
This project was conducted with careful consideration for the professional standards outlined by the British Computer Society (BCS). These guidelines set out a code of ethics and standards of best practice that govern decisions and behaviours in AI research and development. In line with these principles, the project maintained a commitment to public interest, professional competence, and integrity. Key to this was the diligent management of intellectual property and data privacy, ensuring all resources were used responsibly.
9.1.1 - Data & Privacy
While the datasets used in this project are derived from public examination materials, the principles of data privacy, as guided by UK GDPR, were respected throughout. The research adhered to the principle of data minimisation, ensuring that only the information necessary for benchmarking and fine-tuning was processed. This approach ensures the ethical handling of the source material.
9.1.2 - Open-Source Components & Dataset Licenses
The research relied on several open-source and research-licensed resources. Full credit is given to the creators of these tools and datasets, which were essential for this work.
9.1.2.1 - Datasets
The primary benchmark, ITALIC, is available under an open-source MIT license. The fine-tuning dataset, Mult-IT, was used with explicit permission from its authors under a research-only license. All other experimental datasets, including MorphyNet, were also used in accordance with their open-source licenses.
9.1.2.2 - Models & Libraries
The project utilised open-weight models, including Meta's Llama 3.1, Mistral AI's Mistral NeMo and Magistral-Small, and Alibaba's Qwen3. These were used in compliance with their respective community and open-source licenses (e.g., Apache 2.0). The entire implementation was built upon foundational open-source libraries such as Hugging Face transformers, peft, trl, and vLLM.
9.2 - Social & Ethical Implications
The core motivation of this project, as detailed in Section 1.1, is to address a significant ethical issue in modern AI: the strong Anglocentric and Western-centric bias in LLMs. By focusing on improving Italian language capabilities, this work aims to make AI more equitable and inclusive.
9.2.1 - Bias & Cultural Alignment
The performance gap between cultural and linguistic tasks identified in the literature (Section 2.1) represents a form of bias. Models that cannot grasp the fundamental rules of a language can perpetuate stereotypes, misunderstand user intent, and create frustrating experiences. This project directly confronts this by developing techniques to improve linguistic alignment, aiming to create models that are fairer and more effective for Italian users.
9.2.2 - Misinformation
A significant ethical risk is that a more linguistically proficient Italian LLM could be used to generate convincing misinformation or propaganda. While this project's goal is positive, it is crucial to acknowledge that any advancement in language generation technology carries this dual-use risk. The open-weight nature of the models used means that responsible use is reliant on the ethics of the end-user.
9.2.3 - Accessibility
On the positive side, this research contributes to the globalisation and accessibility of AI. By enhancing smaller, efficient models, this work helps ensure that advanced AI is not limited to those with massive computational resources or those who speak English. This promotes a more inclusive digital ecosystem where technology serves a wider range of cultures and languages.
9.3 - Environmental & Sustainability Issues
The computational cost of training and running LLMs has a significant environmental impact due to high energy consumption. This project was designed with sustainability as a core principle.
The decision to focus exclusively on smaller LLMs (under 35B parameters) was a deliberate choice to minimise the environmental footprint. Furthermore, the use of PEFT techniques, specifically LoRA and QLoRA, was central to this sustainable approach. As explained in the methodology (Section 7.2), these techniques allow for significant model specialisation while only training a tiny fraction of the parameters. This drastically reduces the energy and computational resources required compared to full fine-tuning, making the process more sustainable and accessible for the wider research community.
9.4 - Explainability, Trust, & Human Factors
For AI systems to be adopted safely, users must be able to trust them. A key barrier to trust is the "black box" nature of many models, where the reasoning behind an answer is unclear. This project engages directly with this challenge through its focus on reasoning-capable models.
9.4.1 - Risk of Misinterpretation & Over-Reliance
The CoT process explored in Section 3.2 is a powerful tool for explainability. By generating a step-by-step monologue, the model provides a transparent look into its analytical process. However, as the analysis in Section 8.3 showed, an explanation is not a guarantee of correctness. The project found instances where a model produced a coherent reasoning chain but still arrived at the wrong answer due to a flawed knowledge base. This is a critical finding that highlights the ongoing challenge of hallucination and the risk of over-reliance on AI-generated explanations.
9.4.2 - Communicating Uncertainty & Human-in-the-Loop Use
This project's findings underscore the importance of positioning these models as decision support agents, not autonomous decision-makers. The reasoning outputs are designed to augment human intelligence, providing a logical framework that a user can review, critique, and ultimately verify. A human-in-the-loop approach is essential for the responsible deployment of this technology. The user must remain the final authority, using the model's explanation as a guide rather than an infallible proof. This critical awareness is essential for mitigating risks and building genuine, well-placed trust in AI systems.
9.5 - Economic & Commercial Factors
The approach taken in this project has direct and positive economic implications. By focusing on improving smaller, efficient, open-weight models, this research helps to lower the barrier to AI adoption for Italian and European businesses.
Commercially, the high cost of proprietary LLM APIs can be prohibitive, particularly for Small and Medium-sized Enterprises (SMEs). The fine-tuned models produced in this project offer a viable, cost-effective alternative. Businesses can deploy these linguistically competent models for applications such as customer service automation, content creation, and internal data analysis without being locked into expensive, closed-source ecosystems. This democratises access to advanced AI, fostering innovation and allowing a wider range of companies to compete. Furthermore, this work contributes to a more diverse and competitive open-source AI landscape, reducing economic dependency on a small number of large technology corporations.
10 - Conclusion
10.1 - Summary of Work
This project investigated the performance gap between cultural knowledge and linguistic understanding in smaller LLMs for the Italian language. It aimed to test two core hypotheses: first, that modern reasoning capabilities could improve linguistic performance, and second, that a targeted fine-tuning intervention could make these improvements available in a more efficient, non-reasoning mode while keeping reasoning intact. The investigation was a success, validating both hypotheses and producing novel contributions in the process.
The project's novel analytical contribution was the exploration of reasoning (a capability typically reserved for problem-solving tasks like mathematics and programming) as a tool for enhancing linguistic and cultural alignment. The initial evaluation proved this first hypothesis correct. Enabling a model's reasoning process significantly boosted its performance, increasing the "Language Capability" score by an average of 3.93 percentage points. However, a critical challenge emerged during the fine-tuning phase: standard training methods caused the models to suffer a catastrophic loss of their ability to reason.
Solving this required the project's novel technical contribution: a hybrid training method that mixes standard question-answer pairs with synthetically generated CoT examples. This was necessary because traditional methods for training reasoning models, such as RLVR, are computationally intensive, and datasets with pre-existing CoT examples are rare. This hybrid approach successfully met the goals of the second hypothesis by improving the models' performance in both their efficient non-reasoning and advanced reasoning modes. On average, the fine-tuning increased non-reasoning performance by 3.6 percentage points and reasoning performance by 2.93 percentage points, all while completely avoiding the degradation of the reasoning function.
10.2 - Limitations
This research has several limitations, as detailed in Section 8.5. The study focused exclusively on a limited range of smaller, open-weight models due to resource constraints and the novelty of hybrid reasoning architectures. Consequently, the effect of the hybrid fine-tuning technique at a much larger scale remains unexplored. It is possible that reasoning abilities in LLMs exhibit different emergent properties at very large parameter counts, similar to other capabilities. Furthermore, the analysis did not investigate whether fine-tuning on a large corpus of reasoning data would negatively impact non-reasoning performance.
10.3 - Future Work
Looking ahead, future work should extend this investigation to larger models. A key next step would be applying the hybrid training method to larger open-weight models to analyse how the benefits of reasoning scale. Furthermore, with the recent release of very large proprietary hybrid models like Anthropic's Claude 4 series, Google's Gemini 2.5, and OpenAI's GPT-5, an important avenue for future research would be to test if similar fine-tuning strategies can be applied to these state-of-the-art systems to further enhance their multilingual linguistic alignment.
11 - References
[1] A. Ahuja, D. Datta, C. Agarwal, et al., "A Survey of Multilingual Reasoning in Language Models," arXiv preprint arXiv:2502.09457, 2025.
[2] AiSDR, "Reasoning Models vs Standard LLMs," AiSDR Blog, 12 May 2025. [Online]. Accessed: Aug. 20, 2025.
[3] Anthropic, "Introducing Claude 4: Hybrid Mode & Extended Thinking," Anthropic News, 15 May 2025. [Online]. Accessed: Aug. 20, 2025.
[4] V. Basile, L. Bioglio, A. Bosca, C. Bosco, and V. Patti, "UINAUIL: A Unified Benchmark for Italian Natural Language Understanding," in Proc. ACL Demo, 2023, pp. 348–358.
[5] K. Batsuren, T. Toriya, K. Klemmer, and A. Sukhbaatar, "MorphyNet: A Multilingual Database of Derivational and Inflectional Morphology," in Proc. LREC, 2022.
[6] S. Pawar, J. Park, J. Jin, et al., "Survey of Cultural Awareness in Language Models: Text and Beyond," arXiv preprint arXiv:2411.00860, 2024.
[7] X. de la Cruz, M. Falcone, M. Gulotta, and D. Perugini, "BLM-AgrI & BLM-CausI: Bilingually-Enhanced Italian Datasets," in Proc. LREC, 2024.
[8] T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, "QLoRA: Efficient Finetuning of Quantized Large Language Models," arXiv preprint arXiv:2305.14314, 2023.
[9] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, "BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding," in Proc. NAACL, 2019.
[10] A. Fan, J. Bai, Y. Chu, et al., "Large Language Models Are Cross-Lingual Knowledge-Free Reasoners," in Proc. NAACL, 2025.
[11] Google AI, "Gemini 2.5 Pro Technical Report," Google AI Blog, 4 Apr. 2025; AWS Documentation, 2025. [Online]. Accessed: Aug. 20, 2025.
[12] P. Guo, B. Tan, W. Zhang, et al., "Reinforcement Learning from Verifiable Rewards," arXiv preprint arXiv:2501.01345, 2025.
[13] N. Houlsby, A. Giurgiu, S. Jastrzebski, et al., "Parameter-Efficient Transfer Learning for NLP," in Proc. ICML, 2019.
[14] E. Hu, Y. Shen, P. Wallis, et al., "LoRA: Low-Rank Adaptation of Large Language Models," in Proc. ICLR, 2022.
[15] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, et al., "Overcoming Catastrophic Forgetting in Neural Networks," Proc. Natl. Acad. Sci. USA, vol. 114, no. 13, pp. 3521–3526, 2017.
[16] D. Lai, Z. Li, Y. Ma, et al., "CROW: A Commonsense Reasoning Benchmark for Real-World Tasks," in Proc. EMNLP, 2023.
[17] X. Li and P. Liang, "Prefix-Tuning: Optimising Continuous Prompts for Generation," in Proc. ACL, 2021.
[18] C. Long, Z. Ye, L. Chen, et al., "Instruction Fine-Tuning via Parameter-Efficient Methods," arXiv preprint arXiv:2403.04403, 2024.
[19] Mistral AI; A. Rastogi, M. Glénisson, et al., "Magistral: Multilingual Reasoning Models via Reinforcement Learning," Mistral AI Tech. Rep., 2025.
[20] M. Polignano, P. Basile, and G. Semeraro, "On the Impact of Language Adaptation for Large Language Models: A Case Study for Italian," in Proc. CLiC-it, 2023.
[21] Qwen Team, "Qwen2: Scaling Multilingual Language Models with Reasoning," Alibaba DAMO Tech. Rep., 2024.
[22] A. Rao, A. Yerukola, V. Shah, et al., "NormAd: A Framework for Measuring the Cultural Adaptability of Large Language Models," arXiv preprint arXiv:2404.12464, 2024.
[23] A. Radford, J. Wu, R. Child, et al., "Improving Language Understanding by Generative Pre-Training," OpenAI Tech. Rep., 2018.
[24] L. Rinaldi, P. Donzelli, G. Sarti, et al., "Mult-IT: A Large-Scale Native Italian Exam Dataset for LLM Evaluation," in Proc. LREC-COLING, 2024.
[25] A. Seveso, D. Potterì, E. Federici, M. Mezzanzanica, and F. Mercorio, "ITALIC: An Italian Culture-Aware Natural Language Benchmark," in Proc. NAACL, 2025, pp. 1469–1478.
[26] B. Taubenfeld, H. Zhang, D. Zhou, et al., "Confidence-Informed Self-Consistency for Efficient Reasoning," arXiv preprint arXiv:2504.08765, 2025.
[27] J. Tian, S. Liu, R. Xu, et al., "Chain-of-Draft: Fast and Accurate Reasoning with Large Language Models," arXiv preprint arXiv:2503.04567, 2025.
[28] A. Turpin, J. Savelka, F. Leitner, et al., "Faithfulness in Chain-of-Thought Reasoning," arXiv preprint arXiv:2402.09712, 2024.
[29] A. Vaswani, N. Shazeer, N. Parmar, et al., "Attention Is All You Need," in Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 30, 2017, pp. 5998–6008.
[30] N. Vgontzas, E. Florou, P. Mylonas, et al., "Virtual Token Steering for Language Models: Limitations and Opportunities," in Findings of EMNLP, 2023.
[31] X. Wang, J. Wei, D. Schuurmans, et al., "Self-Consistency Improves Chain-of-Thought Reasoning in Language Models," arXiv preprint arXiv:2203.11171, 2022.
[32] J. Wei, X. Wang, D. Schuurmans, et al., "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models," arXiv preprint arXiv:2201.11903, 2022.
[33] S. Yao, Y. Zhao, L. Yu, et al., "Tree-of-Thoughts: Deliberate Reasoning via Language Models," arXiv preprint arXiv:2305.10601, 2023.
[34] P. Zhu, Z. Ren, Y. Li, et al., "A Survey on Quantisation for Large Language Models," IEEE Trans. Neural Netw. Learn. Syst., vol. 35, no. 4, pp. 1–23, 2024.
[35] T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, "QLoRA: Efficient Finetuning of Quantized LLMs," arXiv preprint arXiv:2305.14314, 2023.
[36] R. Brüel-Gabrielsson, J. Zhu, O. Bhardwaj, et al., "Compress then Serve: Serving Thousands of LoRA Adapters with Little Overhead," arXiv preprint arXiv:2407.00066, 2025.
[37] D. Biderman, J. Portes, J. J. Gonzalez Ortiz, et al., "LoRA Learns Less and Forgets Less," arXiv preprint arXiv:2405.09673, 2024.
[38] T. B. Brown, B. Mann, N. Ryder, et al., "Language Models are Few-Shot Learners," arXiv preprint arXiv:2005.14165, 2020.
[39] H. Touvron, T. Lavril, G. Izacard, et al., "LLaMA: Open and Efficient Foundation Language Models," arXiv preprint arXiv:2302.13971, 2023.
[40] S. Bubeck, V. Chandrasekaran, R. Eldan, et al., "Sparks of Artificial General Intelligence: Early Experiments with GPT-4," arXiv preprint arXiv:2303.12712, 2023.
[41] Y. Kim, "Convolutional Neural Networks for Sentence Classification," arXiv preprint arXiv:1408.5882, 2014.
[42] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio, "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modelling," arXiv preprint arXiv:1412.3555, 2014.
[43] S. Hochreiter and J. Schmidhuber, "Long Short-Term Memory," Neural Comput., vol. 9, no. 8, pp. 1735–1780, 1997.
[44] S. Ament, E. Santorella, D. Eriksson, B. Letham, M. Balandat, and E. Bakshy, "Robust Gaussian Processes via Relevance Pursuit," in Proc. NeurIPS, 2024. arXiv preprint arXiv:2410.24222, 2024.
[45] Hugging Face, "Transformers — Trainer class (defaults)," Hugging Face Docs, 2025. [Online]. Accessed: Aug. 20, 2025.
[46] Hugging Face, "Efficient training on a single GPU," Hugging Face Docs, 2025. [Online]. Accessed: Aug. 20, 2025.
[47] Hugging Face, "AutoTrain — LLM fine-tuning parameters," Hugging Face Docs, 2025. [Online]. Accessed: Aug. 20, 2025.
[48] S. Raschka, "Practical Tips for Finetuning LLMs Using LoRA (Low-Rank Adaptation)," Ahead of AI (blog), 19 Nov. 2023. [Online]. Accessed: Aug. 20, 2025.
[49] S. Wang, L. Chen, J. Jiang, B. Xue, L. Kong, and C. Wu, "LoRA Meets Dropout under a Unified Framework," in Findings of ACL, 2024, pp. 1995–2008.
[50] Z. Jiang, L. He, R. Wang, et al., "Instruction-tuned Language Models are Better Knowledge Learners," arXiv preprint arXiv:2403.01744, 2024.
[51] Y. Tong, D. Li, S. Wang, Y. Wang, F. Teng, and J. Shang, "Can LLMs Learn from Previous Mistakes? Investigating LLMs' Errors to Boost Reasoning," arXiv preprint arXiv:2403.20046, 2024.
[52] S. Kim, S. J. Joo, D. Kim, J. Jang, S. Ye, J. Shin, and M. Seo, "The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning," in Proc. EMNLP, 2023, pp. 12685–12708.
[53] G. Puccetti, M. Cassese, and A. Esuli, "The Invalsi Benchmarks: Measuring the Linguistic and Mathematical Understanding of Large Language Models in Italian," Proc. COLING 2025, pp. 6782–6797, 2025.
[54] M. Ismayilzada, D. Circi, J. Sälevä, H. Şirin, A. Köksal, B. Dhingra, et al., "Evaluating Morphological Compositional Generalization in Large Language Models," Proc. NAACL-HLT 2025, pp. 1270–1305, 2025.
[55] Qwen Team, "Qwen/Qwen3-8B," 2024. [Online]. Available: https://huggingface.co/Qwen/Qwen3-8B. [Accessed: 20-Aug-2025].
[56] Mistral AI, "mistralai/Magistral-Small-2506," 2025. [Online]. Available: https://huggingface.co/mistralai/Magistral-Small-2506. [Accessed: 20-Aug-2025].
[57] K. Batsuren et al., "The SIGMORPHON 2022 Shared Task on Morpheme Segmentation," in Proc. 19th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology, Seattle, WA, USA, Jul. 2022, pp. 103–116.
[58] B. M. Montabes de la Cruz et al., "Decoding sound content in the early visual cortex of aphantasic participants," Current Biology, vol. 34, no. 21, pp. 5083–5089.e3, Nov. 2024.
12 - Appendices
12.1 - Appendix A: Reasoning Process Examples
This appendix provides examples of the full outputs generated by reasoning-capable models, as referenced in Section 9.3 Analysis of Reasoning Process. These examples illustrate the step-by-step "thinking" process that the models undertake when their reasoning capabilities are enabled.
12.1.1 - Example 1: Orthography Question
The following example shows the thought process of a Qwen3 model for a question it answered incorrectly with reasoning disabled, but correctly with reasoning enabled.
Question:
Indicare la parola che NON richiede l'iniziale maiuscola.
(Indicate the word that does NOT require an initial capital letter.)
Options:
A) Onu
B) Deputato
C) Picasso
D) Colorado
Model Output (Reasoning Enabled):
<think> Okay, let's see. The question is about morphology, specifically which word doesn't require a capital letter. The options are A) Onu, B) Deputato, C) Picasso, D) Colorado. First, I need to recall the rules for capitalization. Proper nouns usually require capital letters, like names of people, places, or organizations. Let's check each: A) Onu – that's the Italian acronym for United Nations. In Italian, acronyms are usually written in lowercase unless they are proper nouns. Wait, but sometimes they might be capitalized. B) Deputato – this is a common noun in Italian, meaning "deputy." It's not a proper noun, so it shouldn't be capitalized. C) Picasso – that's a proper noun, the name of a famous artist, so it should be capitalized. D) Colorado – that's a proper noun, the name of a state in the US, so it's capitalized. So the answer should be B) Deputato, since it's a common noun and doesn't need a capital letter. Onu might be tricky, but in Italian, acronyms are often lowercase. The other options are clearly proper nouns. So B is the correct answer. </think> FINALE: B
Analysis:
The model's internal monologue demonstrates a clear, logical process. It correctly identifies the grammatical rule, evaluates each option against that rule, and works through ambiguity to arrive at the most logical conclusion.
12.1.2 - Example 2: Incorrect Answer with Flawed Reasoning
Question:
In quale delle seguenti frasi il verbo "essere" ha la funzione di copula?
(In which of the following sentences does the verb "to be" have the function of a copula?)
Options:
A) "Per quell'ora sarò da te"
B) "La riunione fu indetta per le ore dieci"
C) "Per le strade c'era un'insolita animazione"
D) "Gli interessati non furono mai interpellati"
Model Output (Reasoning Enabled):
<think> Okay, let's tackle this question. The user is asking which sentence uses the verb "essere" as a copula. The options are A, B, C, D. First, I need to remember what a copula is. A copula is a verb that links the subject to a complement, often used with "essere" or "avere" in Italian. The main function is to connect the subject to a predicate nominative. Now, looking at the options: A) "Per quell'ora sarò da te" – Here, "sarò" is the future tense of "essere," but it's used as an auxiliary verb with the past participle "stare". So "essere" here is the auxiliary, not the copula. B) "La riunione fu indetta per le ore dieci" – "Fu" is the past tense of "essere," but here it's used as the auxiliary verb for the passive voice. The main verb is "indetta," so "fu" is part of the passive construction. Not a copula. C) "Per le strade c'era un'insolita animazione" – "C'era" is "ci era," which is the contraction of "ci" + "era." Here, "era" is the past tense of "essere," but it's used as the auxiliary verb for the passato prossimo. Wait, but "c'è" is the impersonal form of "essere" (ci è), which can sometimes act as a copula. Hmm, maybe not the best example. D) "Gli interessati non furono mai interpellati" – "Furono" is the past tense of "essere" used as the auxiliary verb for the passive voice. Not a copula. So the answer should be C, because "c'era" is impersonal and can act as a copula in some contexts. </think> FINALE: C
Analysis:
Even though the final answer is incorrect, the model still demonstrates a clear and logical reasoning process. It considers each option, eliminates unlikely candidates based on grammatical rules, and formulates a hypothesis. This shows that the ability to reason has been restored, even if the underlying knowledge is flawed in this specific case.
12.2 - Appendix B: Reasoning Degradation Examples
This appendix provides examples of the outputs from fine-tuned models when their reasoning capabilities were enabled, as referenced in the main report. These examples illustrate the "empty thinking" phenomenon where the models fail to generate a step-by-step thought process.
12.2.1 - Example 1: Incorrect Answer with Empty Reasoning
Question:
Sostituire nella frase seguente la parola "fatto" con una più appropriata: "Poi il dottore mi ha fatto alcune domande sulla mia vita privata."
(Replace the word "fatto" in the following sentence with a more appropriate one: "Then the doctor made me some questions about my personal life.")
Model Output (Qwen3 8B Fine-Tuned, Reasoning Enabled):
<think></think> FINALE: C
Analysis:
The <think> tag is completely empty. The model does not perform any analysis of the sentence, the verb "fatto," or the alternative options. It provides a direct, incorrect answer, behaving identically to its non-reasoning state.
12.2.2 - Example 2: Correct Answer with Empty Reasoning
Question:
Chi è l'autore della poesia "Soldati"?
(Who is the author of the poem "Soldiers"?)
Model Output (Qwen3 8B Fine-Tuned, Reasoning Enabled):
<think></think> La risposta corretta è A
Analysis:
Even when the model arrives at the correct answer, the reasoning process is absent. The <think> tag remains empty, demonstrating that the model is relying on its base knowledge to answer the question directly, rather than using a structured reasoning process. This confirms that the fine-tuning has disabled the model's ability to externalise its thought process.
12.3 - Appendix C: Restored Reasoning Process Examples (Iteration 2)
This appendix provides examples of outputs from models fine-tuned exclusively on synthetic Chain-of-Thought (CoT) data. These examples illustrate that the models have successfully recovered their ability to generate an internal monologue.
12.3.1 - Example 1: Correct Answer with Restored Reasoning
Question:
Individuare la proposizione eccettuativa nel periodo:
"Avrebbe fatto di tutto pur di stare con lei, tranne che lasciare la città in cui era cresciuto."
(Identify the exceptive clause in the sentence: "He would have done anything to be with her, except to leave the city where he had grown up.")
Model Output (Qwen3 8B Fine-Tuned on CoT, Reasoning Enabled):
<think> Okay, the question is about identifying the exceptive clause in the sentence. The sentence is: "Avrebbe fatto di tutto pur di stare con lei, tranne che lasciare la città in cui era cresciuto." The options are A to D. First, I need to recall what an exceptive clause is. It's a clause that introduces an exception to the main statement. In Italian, the structure often uses "tranne che" or "a meno che" to indicate an exception. Looking at the sentence, the main part is "Avrebbe fatto di tutto pur di stare con lei," which means "He would do anything to be with her." Then there's "tranne che lasciare la città in cui era cresciuto." The phrase "tranne che" here sets an exception. The clause after "tranne che" is "lasciare la città in cui era cresciuto," which matches option B. So the answer should be B. </think> FINALE: B
Analysis:
The model successfully generates a detailed thought process. It correctly identifies the grammatical concept (exceptive clause), analyses the sentence structure, and evaluates the options to arrive at the correct answer.
12.3.2 - Example 2: Incorrect Answer with Restored Reasoning
Question:
Chi è l'autore della poesia "Soldati"?
(Who is the author of the poem "Soldiers"?)
Model Output (Qwen3 8B Fine-Tuned on CoT, Reasoning Enabled):
<think> Okay, the question is about who wrote the poem "Soldati" and the options are A) Ungaretti, B) Pavese, C) Leopardi, D) Calvino. I need to recall which poet is known for that work. Leopardi is a classical poet, maybe from the 19th century. Pavese is a 20th-century writer, known for his prose and poetry. Ungaretti is a modernist poet, part of the Hermetic school. Calvino is a novelist, not a poet. "Soldati" sounds like a modern poem, so maybe Pavese? Wait, I think Pavese wrote "Soldati" as part of his poetry. Ungaretti's works are more about war and existential themes, but I'm not sure. Leopardi's poems are more philosophical. Calvino isn't a poet. So the answer is B) Pavese. </think> FINALE: B
Analysis:
Even though the final answer is incorrect (the author is Ungaretti), the model still demonstrates a clear and logical reasoning process. It considers each author, eliminates unlikely candidates based on their typical genres and periods, and formulates a hypothesis. This shows that the ability to reason has been restored, even if the model's underlying knowledge is flawed in this specific case.
12.4 - Appendix D: Code for Injecting CoT to Dataset
The script below takes the CoT from the CSV file and injects it into the dataset for the appropriate question.
import argparse import csv import json import re import unicodedata import difflib from pathlib import Path THINK_RE = re.compile(r"<think\b[^>]*>(.*?)</think>", re.IGNORECASE | re.DOTALL) PUNCT_MAP = { "'": "'", "''": '"', "„": '"', "«": '"', "»": '"', "\u00A0": "", "‐": "-", "–": "-", "—": "-", } DROP_PUNCT_PATTERN = re.compile(r"[^\w\s]", flags=re.UNICODE) def strip_diacritics(s: str) -> str: nfkd = unicodedata.normalize("NFD", s or "") return "".join(ch for ch in nfkd if unicodedata.category(ch) != "Mn") def tidy(s: str) -> str: s = unicodedata.normalize("NFKC", s or "") for a, b in PUNCT_MAP.items(): s = s.replace(a, b) return " ".join(s.split()).strip().lower() def loose_key(s: str) -> str: s = strip_diacritics(tidy(s)) s = DROP_PUNCT_PATTERN.sub("", s) return "".join(s.split()) def extract_thinking(raw_response: str) -> str | None: parts = [m.strip() for m in THINK_RE.findall(raw_response)] return "\n\n".join(p for p in parts if p) if parts else None def build_jsonl_index(jsonl_path: Path): lines = [] keys_tidy = set() keys_loose = set() with jsonl_path.open("r", encoding="utf-8") as f: for line in f: raw = line.rstrip("\n") if not raw.strip(): continue try: obj = json.loads(raw) q = obj.get("question", "") k1 = tidy(q) k2 = loose_key(q) if k1: keys_tidy.add(k1) if k2: keys_loose.add(k2) lines.append((raw, obj, k1, k2)) except json.JSONDecodeError: lines.append((raw, None, "", "")) return lines, keys_tidy, keys_loose def load_thinking_map(csv_path: Path, keys_tidy, keys_loose, fuzzy_threshold: float): map_key_to_think = {} loose_key_list = list(keys_loose) with csv_path.open(newline="", encoding="utf-8") as f: reader = csv.DictReader(f) for row in reader: if not (row.get("is_correct") == "true" and row.get("has_thinking") == "true"): continue thinking = extract_thinking(row.get("raw_response", "")) if not thinking: continue q = row.get("question", "") k1 = tidy(q) k2 = loose_key(q) chosen_key = None if k1 and k1 in keys_tidy: chosen_key = k1 elif k2 and k2 in keys_loose: chosen_key = k2 elif k2 and loose_key_list: best = difflib.get_close_matches(k2, loose_key_list, n=1, cutoff=fuzzy_threshold) if best: chosen_key = best[0] if chosen_key and chosen_key not in map_key_to_think: map_key_to_think[chosen_key] = thinking return map_key_to_think def main(): parser = argparse.ArgumentParser(description="Merge thinking into JSONL subset (robust).") parser.add_argument("--jsonl-in", required=True, help="Path to original JSONL.") parser.add_argument("--csv", required=True, help="Path to CSV with thinking.") parser.add_argument("--thinking-out", required=True, help="Path to write thinking JSONL.") parser.add_argument("--no-thinking-out", required=True, help="Path to write no-thinking JSONL.") parser.add_argument("--fuzzy-threshold", type=float, default=0.985) args = parser.parse_args() jsonl_lines, keys_tidy, keys_loose = build_jsonl_index(Path(args.jsonl_in)) thinking_map = load_thinking_map(Path(args.csv), keys_tidy, keys_loose, args.fuzzy_threshold) with open(args.thinking_out, "w", encoding="utf-8") as fthink, \ open(args.no_thinking_out, "w", encoding="utf-8") as fno: for raw_line, obj, k1, k2 in jsonl_lines: if obj is None: fno.write(raw_line + "\n") continue thinking = None if k1 and k1 in thinking_map: thinking = thinking_map[k1] elif k2 and k2 in thinking_map: thinking = thinking_map[k2] if thinking: out_obj = dict(obj) out_obj["thinking"] = thinking fthink.write(json.dumps(out_obj, ensure_ascii=False) + "\n") else: fno.write(raw_line + "\n") if __name__ == "__main__": main()
12.5 - Appendix E: Computing Statistical Significance
The script below computes the statistical significance using McNemar's test and also computes Chi-Squared by taking in the CSV files containing each question's response generated by the benchmarks.
#!/usr/bin/env python3 """ Compute McNemar's test from two question-by-question CSVs. Reports: - Per-file accuracy - Intersection-only accuracy - 2×2 table - McNemar (chi-square + exact) - Discordant OR + 95% CI """ import argparse import csv import math import re import unicodedata from collections import defaultdict from pathlib import Path from typing import Dict, List, Optional PUNCT_MAP = { "'": "'", "''": '"', "„": '"', "«": '"', "»": '"', } DROP_PUNCT = re.compile(r"[^\w\s]", flags=re.UNICODE) def strip_diacritics(s: str) -> str: nfkd = unicodedata.normalize("NFD", s or "") return "".join(ch for ch in nfkd if unicodedata.category(ch) != "Mn") def tidy(s: str) -> str: s = unicodedata.normalize("NFKC", s or "") for a, b in PUNCT_MAP.items(): s = s.replace(a, b) return " ".join(s.split()).strip().lower() def loose_key(s: str) -> str: s = strip_diacritics(tidy(s)) s = DROP_PUNCT.sub("", s) return "".join(s.split()) def as_bool(x) -> bool: return str(x or "").strip().lower() in {"1", "true", "t", "yes", "y"} def row_correct(row: Dict[str, str]) -> Optional[bool]: ca = row.get("correct_answer") pa = row.get("predicted_answer") if ca is None or pa is None: return None return tidy(ca) == tidy(pa) def key_for_row(row: Dict[str, str]) -> Optional[str]: q = loose_key(row.get("question", "")) if q: return q idx = str(row.get("index", "")).strip() return f"idx:{idx}" if idx else None def exact_binom_two_sided(b: int, c: int) -> float: n = b + c if n == 0: return float("nan") k = min(b, c) logp = -n * math.log(2.0) logsum = -math.inf for i in range(0, k + 1): logsum = math.logaddexp(logsum, logp) if i < k: logp += math.log(n - i) - math.log(i + 1) p = 2.0 * math.exp(logsum) return min(p, 1.0) def chisq1_sf(x: float) -> float: if x < 0 or math.isnan(x): return float("nan") return math.erfc(math.sqrt(x) / math.sqrt(2.0)) def read_csv_build_maps(path: Path): with path.open("r", encoding="utf-8-sig", newline="") as f: reader = csv.DictReader(f) rows = [] key_to_rows = defaultdict(list) for row in reader: key = key_for_row(row) if key is None: continue row["_correct_bool"] = row_correct(row) key_to_rows[key].append(row) rows.append(row) total = len(rows) usable = sum(1 for r in rows if r.get("_correct_bool") in (True, False)) correct = sum(1 for r in rows if r.get("_correct_bool") is True) return { "total_rows": total, "usable_rows": usable, "correct": correct, "accuracy": correct / usable if usable else float("nan"), "key_to_rows": key_to_rows, } def pair_and_count(map_a, map_b): keys = sorted(set(map_a.keys()) | set(map_b.keys())) n00 = n01 = n10 = n11 = 0 for k in keys: a_list = map_a.get(k, []) b_list = map_b.get(k, []) if not a_list or not b_list: continue a_row = a_list[0] b_row = b_list[0] ca = a_row.get("_correct_bool") cb = b_row.get("_correct_bool") if ca not in (True, False) or cb not in (True, False): continue if not ca and not cb: n00 += 1 elif not ca and cb: n01 += 1 elif ca and not cb: n10 += 1 else: n11 += 1 return n00, n01, n10, n11 def main(): parser = argparse.ArgumentParser(description="McNemar's test from two CSVs") parser.add_argument("--csv-a", required=True, help="Path to CSV A") parser.add_argument("--csv-b", required=True, help="Path to CSV B") parser.add_argument("--label-a", default=None) parser.add_argument("--label-b", default=None) args = parser.parse_args() path_a = Path(args.csv_a) path_b = Path(args.csv_b) label_a = args.label_a or path_a.stem label_b = args.label_b or path_b.stem map_a = read_csv_build_maps(path_a) map_b = read_csv_build_maps(path_b) n00, n01, n10, n11 = pair_and_count(map_a["key_to_rows"], map_b["key_to_rows"]) pairs = n00 + n01 + n10 + n11 b = n01 c = n10 chi2 = float("nan") p_chi = float("nan") p_exact = float("nan") if (b + c) > 0: chi2 = (abs(b - c) - 1) ** 2 / (b + c) p_chi = chisq1_sf(chi2) p_exact = exact_binom_two_sided(b, c) acc_a_full = map_a["accuracy"] acc_b_full = map_b["accuracy"] acc_a_pair = (n10 + n11) / pairs if pairs else float("nan") acc_b_pair = (n01 + n11) / pairs if pairs else float("nan") diff_pair = acc_b_pair - acc_a_pair print(f"Files: A='{path_a}' B='{path_b}'") print(f"Labels: A='{label_a}' B='{label_b}'") print("-" * 72) print("Per-file accuracy (full, each file alone):") print(f" {label_a}: {acc_a_full:.2%}") print(f" {label_b}: {acc_b_full:.2%}") print("-" * 72) print("Intersection-only accuracy (matched pairs):") print(f" Pairs used: {pairs}") print(f" {label_a}: {acc_a_pair:.2%}") print(f" {label_b}: {acc_b_pair:.2%}") print(f" Difference (B - A): {diff_pair:+.2%}") print("-" * 72) print("2×2 table (A vs B):") print(f" B Wrong B Right") print(f" A Wrong {n00:4d} {n01:4d}") print(f" A Right {n10:4d} {n11:4d}") print(f" Discordant: b = {b}, c = {c}") print("-" * 72) print("McNemar's test (intersection only):") if (b + c) == 0: print(" No discordant pairs (b+c=0). Test not defined.") else: print(f" Chi-square (with continuity): {chi2:.6f}") print(f" p-value (approx, df=1): {p_chi:.6g}") print(f" p-value (exact binomial): {p_exact:.6g}") if __name__ == "__main__": main()
12.6 - Appendix F: Full Results Tables
12.6.1 - Table 2: Model Details
| Model Name | Parameters (B) | Architecture | Fine-Tuned | Notes |
|---|---|---|---|---|
| Llama 3.1 8B Ita | 8 | Transformer Decoder | Yes | Italian-specific fine-tune |
| Mistral NeMo | 12 | Transformer Decoder | No | Multilingual baseline |
| Qwen3 0.6B | 0.6 | Transformer Decoder | No | Smallest Qwen3 model |
| Qwen3 1.7B | 1.7 | Transformer Decoder | No | Small Qwen3 model |
| Qwen3 4B | 4 | Transformer Decoder | No | Mid-size Qwen3 model |
| Qwen3 8B | 8 | Transformer Decoder | No | Target model for fine-tuning |
| Qwen3 14B | 14 | Transformer Decoder | No | Large Qwen3 model |
| Qwen3 32B | 32 | Transformer Decoder | No | Largest Qwen3 model |
| Magistral-Small | 24 | Transformer Decoder | No | Multilingual reasoning model |
12.6.2 - Table 2: Culture & Common Sense Reasoning Results
| Model | Total | Culture | Commonsense | History | Geography | Literature | Art | Civic Ed | Tourism |
|---|---|---|---|---|---|---|---|---|---|
| Llama 3.1 8B Ita | 70.49 | 72.96 | 71.50 | 77.66 | 79.06 | 67.17 | 70.78 | 71.50 | 71.33 |
| Mistral NeMo | 68.68 | 69.71 | 69.27 | 74.95 | 76.43 | 69.31 | 66.02 | 69.71 | 67.45 |
| Qwen3 8B | 70.17 | 70.47 | 70.30 | 73.13 | 70.47 | 68.90 | 69.20 | 71.10 | 70.80 |
| Qwen3 8B [V3] | 73.81 | 73.29 | 72.10 | 76.50 | 74.00 | 71.20 | 72.90 | 73.80 | 72.10 |
12.6.3 - Table 3: Language Understanding Results
| Model | Total | Language | Morphology | Orthography | Syntax | Lexicon | Synonyms |
|---|---|---|---|---|---|---|---|
| Llama 3.1 8B Ita | 66.83 | 66.83 | 51.71 | 52.29 | 53.52 | 81.31 | 81.27 |
| Mistral NeMo | 63.12 | 63.12 | 52.86 | 56.23 | 54.57 | 79.90 | 74.03 |
| Qwen3 8B | 69.73 | 69.73 | 64.20 | 66.10 | 65.40 | 81.50 | 78.90 |
| Qwen3 8B [V3] | 74.58 | 74.58 | 68.90 | 71.20 | 69.80 | 84.10 | 82.30 |